Todas las fases del proceso de elaboración de cerveza son igual de importantes, pero si hay uno que por su complejidad y variabilidad es clave, es el macerado. Aunque es bien cierto que, sobre todo cuando empiezas, te basta con “intentar no estropear nada”, poco a poco es conveniente profundizar en lo que ocurre cuando mezclas agua y grano.
Según consigues más control del equipo y de la teoría cervecera, te das cuenta de que en la etapa de macerado hay un gran campo donde investigar y un punto de mejora fundamental. Sinceramente, opino que si sabemos lo que ocurre dentro de tu macerador y lo entendemos, aunque sea de manera superficial, podemos tener más campo de juego a la hora de diseñar nuestras recetas y elaborarlas.
En este artículo vamos a dar un repaso a lo que ocurre cuando juntamos nuestra malta molida con el agua calentita y a intentar comprender cómo podemos manejarlo para favorecer los resultados de nuestra cerveza casera.
Este post no se va a encargar de la manera mecánica o práctica de cómo operar el macerado. Es decir, no va a hablar de métodos de lavado o si es mejor un HERMS, o un RIMS, o cómo hacer el recirculado perfecto. Va a hablar de la teoría que se encierra en el macerado, verá el resultado de algún experimento en la práctica y expondrá las variables de las que disponemos los jombrigüeres para que luego, cada cual, haga de su capa un sayo.
Y es necesario aclarar que durante todo el post nos referimos a macerados por infusión simple. Dejamos de lado la decocción, y casi de lado los macerados con escalones de temperatura o los macerados asistidos y cualquier otro tipo de mezcla de los ya nombrados… Vamos a lo simple, que ya habrá tiempo de complicarse.
El concepto simple
Si tuvieras que explicar qué es el macerado a tu abuela, obviando tecnicismos y factores variables, podríamos decir que el macerado consiste en ‘extraer’ los azúcares que hay en la malta (y otros adjuntos) y conseguir diluirlos en agua. Este caldo o sopa de cereales azucarada (no dejéis de probar todos los mostos que consigáis) se denomina “mosto”, en analogía con el jugo de la uva cuando la exprimes, antes de fermentarse y tener vino.
La comparación con el vino a veces resulta muy gráfica. Casi todo el mundo entiende que si aplastas las uvas y pones a fermentar el zumo resultante (lleno de azúcares), cosa que basta con mezclarlo con la propia piel de la uva (llena de levaduras salvajes), acabas teniendo vino. No estoy diciendo si consigues un vino de buena calidad, pero acabas teniendo vino. Dado que la cerveza también es una bebida alcohólica fermentada y que si aplastamos la cebada no sale ningún jugo (al contrario que con las uvas), tenemos que añadirlo a un medio líquido para obrar el milagro.
Sin embargo, aquí es cuando la cosa empieza a complicarse, ya que entran en juego muchos factores que van a influir en el resultado, a favor o en contra. Desde la composición propia del agua, de la propia malta, de las temperaturas, del ratio agua/malta y del propio tiempo en el que ocurre todo esto, entre otras cosas, vamos a conseguir un mosto de uno u otro tipo.
De manera simplista, podemos decir que dentro de la malta nos encontramos con una gran cantidad de almidón por un lado, y con cierto contenido de diferentes enzimas, por el otro. Gracias a nuestra intervención, hidratando la malta con agua caliente, vamos a conseguir activar esas enzimas, las cuales están “programadas” para descomponer el almidón en azúcares más simples (cadenas más cortas de azúcares), que finalmente, podrán servir como alimento de las levaduras durante la fermentación.
Una definición igual de simple pero más acertada sería que lo que vamos a hacer mediante el macerado, es convertir los almidones que están en los cereales a macerar (no solo malta o cebada, sino también maíz, avena, trigo, arroz…) en azúcares que sean fermentables, esto es, que la levadura pueda usarlos para fermentar. Y esta “conversión” solo ocurrirá mediante un proceso llevado a cabo por enzimas que de manera natural se encuentran en la malta.
Complicando el concepto
Empecemos por resaltar un hecho notable: en los tiempos que corren, las malterías han avanzado mucho su conocimiento de los procesos y las técnicas actuales permiten producir maltas muy efectivas a la hora de hacer un macerado. A estas maltas se les conoce como “maltas bien modificadas”, y facilitan mucho la labor del cervecero, que tiende a despreocuparse de ciertas problemáticas que había en el pasado. Por esta cuestión, muchas de las publicaciones más clásicas acerca de elaborar cerveza en casa están un poco obsoletas. Y esto incide en los procesos de hoy.
Hace siglos, las maltas no estaban tan modificadas y podemos decir que había que “acabar de modificarlas” durante el macerado. Eso implicaba algún paso que otro que en la actualidad podemos obviar. Si te atrevieras a maltear cebada en casa, probablemente no lo harías tan bien como una maltería y tendrías que preocuparte de averiguar qué pasos hacían los cerveceros clásicos para complementar un malteado ineficaz. Nos vamos a permitir del lujo de dejar de lado pasos engorrosos como la degradación de los betaglucanos y de las proteínas.
A modo de curiosidad, podemos decir que se hacían varios escalones a bajas temperaturas (35 °C, 45 °C, 55 °C) para activar enzimas desramificadoras y proteínas que beneficiarán los procesos que están por llegar. Las enzimas que actúan en ese rango bajo de temperaturas se conocen como proteasas, y centran su actividad en las proteínas del mosto.
Otro tipo de enzimas, conocidas como amilasas, nos van a dar mejores satisfacciones y son las que se van a llevar todo nuestro amor y todo nuestro cariño.
Las enzimas amilasas
Nuestras “más mejores” amigas durante el macerado van a ser dos enzimas concretas, que van a pilotar casi todo el proceso (y pongo “casi todo el proceso” porque además de que poner “todo” es inexacto, tengo miedo de que un cervecero fanático me escriba un e-mail poniéndome de vuelta y media), que son las alfa-amilasas y la beta-amilasas. En realidad, son proteínas y son unas auténticas picadoras, cortadoras, desmenuzadoras, acuchilladoras y destrozadoras de almidones.
- La alfa-amilasa trabaja más cómoda en rangos de temperatura más altos que su prima la beta-amilasa, y convierte el almidón en dextrinas. Estas dextrinas son cadenas largas de azúcares que pueden ser no digeribles por la levadura. Un mosto “dextrinoso” es un mosto macerado en un rango de temperatura alto, cercano a los 70 °C y que (teóricamente) va resultar en una cerveza con un dulzor residual, compuestos complejos de sabor derivados de estos azúcares y con cuerpo.
- La beta-amilasa trabaja mejor en un rango de temperatura más bajo que las alfa-amilasas, y pulveriza partes del almidón y de las dextrinas que ha fabricado la alfa-amilasa en azúcares sencillos, como la maltosa, fácilmente asimilable por la levadura. Es favorecida por empastes ligeros. Se desactiva alrededor de los 70 °C. En rangos generales, cuánto más baja sea la temperatura del macerado, más fermentable será el mosto y la cerveza resultante, más seca.
Aquí llega entonces el primer cisma del macerado. En las guías para principiantes, siempre se aconsejan distintos rangos de temperatura de macerado… que si entre 66-68 °C, que si 63-67 °C, que si 65-66 °C…. Si bien es cierto que a un jombrigüer novato no vas a calentarle la cabeza con todos estos factores, también es verdad que llega el momento de ver un poco más con detalle qué ocurre en el macerado.
A alguien que empieza, lo que más le gusta es ver a su airlock borbotear como un adolescente que acaba de descubrir una plataforma gratuita de videos eróticos en internet. Y dejarse, por el momento, de alfa-amilasas, betaglucanos, dextrinas y pH. Pero si con el tiempo no avanzas, el perfil de las cervezas que vayas elaborando será muy parecido, en cuanto a cuerpo. No hay nada malo en eso, pero hay que tener en cuenta que no todos los estilos tienen el mismo cuerpo, y lo mucho que favorece un cuerpo pleno a ciertos estilos contundentes…
Si queremos jugar con el cuerpo de las cervezas (azúcares residuales, o densidades finales más altas) o con sabores más complejos provenientes de la malta, tendremos que favorecer el trabajo de la alfa-amilasa y dificultar el de la beta-amilasa. Veremos, además, que esto no es tan fácil hoy en día por las maltas modernas y la alternativa.
Como veremos muy pronto, hay cuatro factores qué podemos modificar para ajustar nuestro macerado. Un factor es el tiempo de macerado, otro, el rango de temperatura, el tercero sería el pH, y el cuarto, el ratio agua:grano del empaste.
Hay que dejar claro desde un principio que, aunque las condiciones no sean del todo óptimas para una enzima, no quiere decir que la enzima no siga trabajando. No son enzimas cuadriculadas, que funcionan a golpes de resortes, ni sindicalistas. Seguirán actuando, pero de manera más lenta, por lo que la enzima que tenga las condiciones más favorables será la que actúe de manera notable.
Don Almidón y Doña Dextrina
Hemos hablado tanto de almidones como de dextrinas, pero no hemos explicado, al menos de forma orientativa, lo que son.
A lo bruto, podemos decir que el almidón no es otra cosa que un montón de azúcares, sencillos y no tan sencillos, unidos entre sí. Si el almidón se hubiera descubierto hoy, los científicos le hubieran bautizado como “azucarako” y lo hubieran definido como “algo petado de glucosas todas juntas y apelotonadas”.
El almidón de la malta se encuentra en dos formas (que la gente que es muy lista, los llama “polímeros de glucosa”), una de ellas es la amilosa (un 25%) y la otra, la amilopectina (el otro 75%). La amilosa son cadenas largas de glucosa no ramificadas, mientras que las amilopectinas son más complejas, puesto que las cadenas de glucosa sí están ramificadas (tienen forma de árbol). La beta-amilasa y las alfa-amilasas van a atacar a cada uno de los almidones de manera diferente, pero el resultado serán cadenas de más cortas de azúcares.
Los textos más avanzados sobre la química del macerado te explican con detenimiento los enlaces de la molécula de glucosa de almidón que es atacada por cada enzima y ponen muchas palabras con muchas letras, pero creo que lo mejor es una visión pragmática del asunto (y divertida, dentro de lo que cabe). Esto es, que hay que tener claro que la alfa-amilasa va a romper el almidón en cadenas más cortas de azúcares, de los cuales muchos serán fermentables, pero también va a crear dextrinas, que no lo son tanto. En cambio, la beta-amilasa, va a actuar en los finales de las cadenas de azúcares, rompiéndolas en cadenas muy cortas (como, por ejemplo, dos azúcares, o sea, disacáridos, como la maltosa).
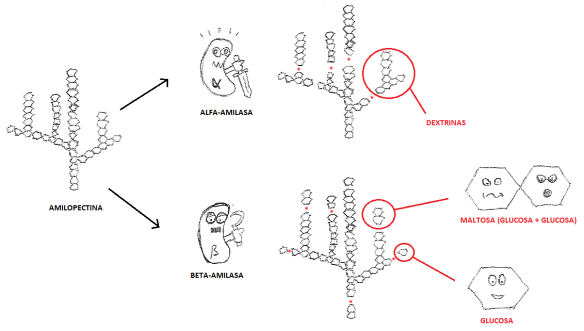
Así, al final del todo tendremos un mosto lleno de azúcares simples (monosacáridos como la glucosa), de disacáridos (dos azúcares, como por ejemplo, dos glucosas juntas, que se conocen como “maltosa”), algunas cadenas de trisacáridos (tres glucosas juntas, conocidas como “maltrotriosa”) y las ya archifamosas dextrinas, que son cadenas de azúcares más largas, menos digeribles por la levadura, por lo que no van a fermentar bien y una parte (más grande o más pequeña) se van a quedar en el mosto, añadiendo complejidad y cuerpo a la cerveza.
Por tanto, en realidad, el macerado se trata de bajar y subir palancas imaginarias de nuestra máquina imaginaria para ajustar las proporciones de azúcares fermentables y dextrinas, y conseguir la cerveza que nos proponíamos: con más o menos cuerpo, más dulce o más seca.
Y las enzimas, ¿son gratis?
Ya se ha dicho que la malta guarda en su interior las enzimas necesarias para desmontar (licuar) los almidones que también vienen con la malta… ¡un grano de malta es un kit completo! Sin embargo, conviene matizar este punto para un total entendimiento del proceso. Es necesario un cierto equilibrio/proporción entre almidones y enzimas, para lograr un macerado óptimo. Por ejemplo, en el artículo acerca de usar arroz en nuestros macerados [¡plink!] comentábamos el problema al que se enfrentaron los colonos europeos en los Estados Unidos cuando querían usar maltas de cebada americana de 6 hileras. El contenido en enzimas era demasiado, lo que provocaba efectos indeseables por dicho exceso de proteínas (como la turbidez), así que se les ocurrió el uso de arroz como fuente de almidones para compensar la proporción con las enzimas.
En el artículo titulado “El secreto está en la malta”, ya introdujimos el concepto de poder diastásico [¡plink!] o como me gusta llamarlo, el “poderío enzimático”, que habla justo esta circunstancia y que no vamos a repetir aquí, pero que conviene tener claro.
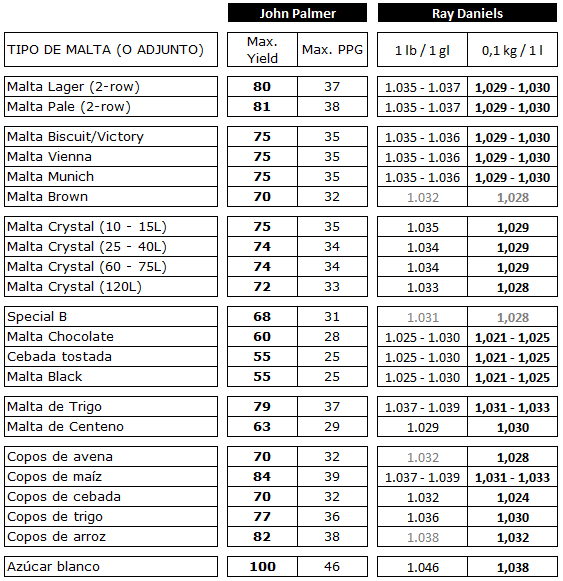
En nuestros macerados caseros, rara vez tendremos problemas como los de los colonos americanos, pero existe la posibilidad de que incluyamos un porcentaje elevado de grano sin contenido enzimático y tengamos el problema inverso: muchos almidones y pocas enzimas que los trabajen. La recomendación más extendida es no bajar la malta base (Pale/Pils) por debajo del 70%, y si lo hacemos, recordemos que otras maltas como la Munich o Vienna tienen menos enzimas, y que van teniendo aún menos cuanto más oscuras son, ya que el propio proceso de fabricación aniquila las enzimas.
Por poner ejemplos, las maltas bases pueden tener entre un 100 – 140 °L de poderío enzimático (a veces más, como la malta de 6 hileras, o a veces menos, como ciertas maltas inglesas), la Munich ronda los 70 °L, pero si está muy tostada, bajaría a los 20-30 °L. La malta chocolate, la Black y las Crystal, tienen un 0 °L, o lo que es lo mismo: no contiene enzimas.
Fases del macerado, con almidones y a lo loco
Este “proceso enzimático”, que conocemos como macerado, lo podrás leer en muchos sitios como “sacarificación”, debido a que es la palabra técnica que define al proceso de romper azúcares complejos (como el almidón) en sus compuestos más simples. Sin embargo, en realidad es el paso final del macerado, cuando ocurre el milagro y las amilasas han hecho chop-suey con el almidón.
Las fases del macerado, teniendo en cuenta el proceso químico, y no el mecánico de gestionar y mover el mosto, descritas de forma escueta, serían las siguientes:
Remojado
Donde hacemos la mezcla de malta molida y agua caliente, para ajustarlo a una temperatura o rango de temperatura concreto, y aprovechamos (una vez la mezcla se haya asentado), para medir el pH y ajustarlo si es necesario.
Gelatinización
La gelatinización llega a los oídos de los jombrigüeres tarde o temprano. En realidad, resulta un concepto familiar por la popularidad de la palabra “gelatina”, y se acopla a nuestro vocabulario de manera normal. Pero… ¿sabemos lo que es?
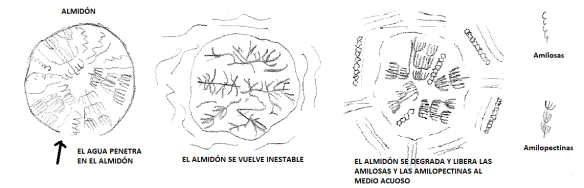
Cuando tienes la malta en su saco, los almidones no están disponibles, están dentro del grano, y hay que facilitar su extracción. Lo primero que hacemos es romper el grano, a través de la molienda, llenando todo de polvo, pero a la vez vamos a permitir que el “medio almidonado” del interior del grano quede expuesto.
Ahora tenemos que pensar a nivel molecular. El almidón empieza a absorber agua, por lo que se va hinchando. Esta hinchazón provocada por el agua empieza a alterar la estructura del almidón, volviéndose inestable. Si la temperatura del agua es la adecuada, el almidón acabará descomponiéndose en partes más pequeñas, así que el contenido de la molécula del almidón se “funde” con el agua (en realidad, se combina), lo que provoca cierta pastosidad consistente, como si estuviéramos haciendo unas gachas.
Con esta impresionante imagen mental, donde una molécula de almidón empieza a hincharse con el agua y se degrada hasta deshacerse por completo como la bruja del Mago de Oz, pasamos a conocer los conceptos básicos: ese punto, cuando el almidón se degrada en partes más pequeñas es lo que conoce como “temperatura de gelatinización”. Y se da la circunstancia de que cada fuente de almidón gelatiniza a temperaturas distintas. Un almidón de la malta de cebada gelatiniza entre los 63 y los 69 °C (como siempre, dependiendo del libro que mires, encontrarás variaciones en esta información), aunque el almidón de la cebada cruda, sin maltear, gelatiniza entre los 60 y los 62 °C. Otros ejemplos, serían: un almidón proveniente de la patata gelatiniza entre los 55 y los 71 °C, el del trigo entre los 52 y los 66 °C y el del arroz, pues… ¡depende del arroz!, los hay del rango 61-82, del 66-68, del 71-74…
Al fenómeno químico de que una sustancia orgánica como el almidón de descomponga por acción del agua se le denomina “hidrólisis”.
Licuefacción
Y llegados al punto donde el almidón ha sido gelatinizado, las partes más pequeñas, que son las amilosas y las amilopectinas, están libres en el agua, llega el momento de la licuefacción. La licuefacción es la fase del macerado donde entran en juego las enzimas y empiezan a partir las cadenas largas de azúcares en otras más pequeñas.
Sacarificación
El mosto es ahora un caldo lleno de dextrinas. Esto es, cadenas largas de azúcares (de incluso 10 o 20 moléculas de glucosa) que no van a poder ser metabolizadas por la levadura, así que necesitamos un nuevo paso de degradación, para conseguir esas moléculas de 1 o 2 azúcares (glucosa o maltosa). Y el proceso en sí por el cual una enzima rompe una cadena compleja de azúcares en otra más pequeña de monosacáridos o disacáridos, se denomina “sacarificación”. Es justo la parte que nos gusta manejar a los cerveceros para hacer el mosto a nuestra medida, y que está descrita con más detenimiento en otras partes del artículo.
Las cuatro palancas
Antes nos referíamos al macerado como un juego de palancas que podemos ajustar para conseguir diferentes resultados. Pues esas palancas, en concreto, son cuatro, y sobre ellas están las siguientes etiquetas: tiempo, temperatura, pH y empaste. Si se entiende lo que ocurre en el macerado, a la hora de crear una receta, y luego, elaborarla, el jombrigüer tiene el control para poder jugar con estas palancas y conseguir la cerveza que quiera. O al menos, en teoría.
Primera palanca | El tiempo
Dando el suficiente tiempo de trabajo a las enzimas, conseguiremos un macerado más eficaz (ergo, rendimientos más altos), pero un macerado de cinco horas es bastante aburrido, y costoso de mantener (en energía, que siempre es dinero). Así que hay conseguir la conversión del almidón en azúcares simples en un tiempo razonable.
Evidentemente, cuanto más tiempo se emplee en el rango de temperatura óptimo para cada una de las enzimas, va a tener una potenciación de la actividad. Y dicha actividad, un efecto concreto en el mosto resultante, que no siempre va a ser positivo.
Por ejemplo, en rangos bajos de temperatura (esos que hemos dicho que es mejor olvidarnos si usamos maltas bien modificadas), un breve tiempo de actividad de las proteasas va a favorecer la claridad de la cerveza. Sin embargo, si el tiempo de actividad es prolongado, incidirá directamente en un problema en la generación de la espuma de servido. Por estas cosas es preferible no gestionar el macerado al azar, sin saber qué consecuencias tiene cada decisión.
Por tanto, un mayor tiempo dedicado al rango favorable de la alfa-amilasa va a provocar una mayor proliferación de las dextrinas, y más tiempo en rangos bajos de temperatura, favorecerá la actuación de la beta-amilasa y el mosto será más fermentable, por lo que conseguiremos una mayor atenuación al fermentar, más alcohol y una cerveza más seca.
A pesar de lo dicho, se dice que, a partir de los 60 minutos de macerado, la actividad enzimática se empieza a ralentizar, lo que no quiere decir que se detenga. Está comprobado que macerados más duraderos tienen un mejor rendimiento.
Existe un método muy rudimentario para controlar la actividad de la sacarificación, que es mediante la prueba del yodo, que vamos a comentar más adelante. Mediante esta prueba, sabrás si merece la pena alargar el macerado o ya ha transcurrido el tiempo suficiente.
Macerados muy eficientes completan la conversión en media hora, aunque lo usual y más extendido es apuntar a una hora para asegurarse una conversión completa. Como esto depende mucho de los equipos, del volumen del lote y de procesos auxiliares (como remover el empaste o recircular el mosto), no hay una guía fija que seguir y una vez más hay que recurrir a la experiencia.
Segunda Palanca | Temperatura
A estas alturas, ya sabemos de forma más que intuitiva que la temperatura del macerado incidirá de forma directa en la actividad de nuestras enzimas amigas. Además, a lo largo y ancho de internet podemos encontrar diferentes consejos acerca de cómo manejarse en este campo e incluso rangos contradictorios sobre los rangos de temperatura aconsejables para cada enzima. Además, los jombrigüeres-maniacos querrán clavar la temperatura de su macerado para lograr un clímax enzimático divino que impulse a las beta-amilasas a trabajar marcándose una coreografía grupal hasta la extenuación… Y mi consejo es no volverse muy loco. La “fluctuosidad” de los elementos de medición que tenemos en casa deja mucho que desear, así como que posiblemente, la temperatura de tu macerador no sea única en todo el volumen macerado. Es probable que la superficie tenga una temperatura, el fondo otra (sobre todo si aplicas calor por ahí) y diferentes puntos intermedios, otras distintas. Incluso, si te trabajas un sistema de recirculación continua para evitar diferentes zonas de temperatura, es probable que en realidad lo que estés consiguiendo es que la temperatura te fluctúe ciertos Celsius (o parte de ellos) de manera cíclica. Mantened la calma. Estamos haciendo cerveza en casa, las vidas de millones de personas no dependen de la temperatura de tu macerado, así que apunta a la temperatura que quieres/necesitas y hazlo lo mejor que puedas para ajustarla. Además, como veremos enseguida, dependiendo de la publicación que consultes, tendrás un baile de temperaturas y rangos que te producirá palpitaciones malsanas si lo que pretendes es controlarlo todo al dedillo. Y para rematar, veremos un par de experimentos un tanto descorazonadores.
En cualquier caso, una temperatura demasiado alta, destruirá las enzimas o las dejará inactivas (posiblemente para siempre), y una temperatura demasiado baja, no conseguirá activarlas, al menos por completo. No hay un consenso al 100% entre toda la literatura que he consultado para definir el rango concreto de temperaturas para la alfa y la beta amilasa. Si bien el rango del “escalón de sacarificación” normalmente va de 65 °C a 71 °C, ya va a depender del estilo de cerveza concretar qué temperatura (o temperaturas) usar. No es lo mismo elaborar una Scotch Ale donde buscamos cierto dulzor residual maltoso, y abusaríamos de la confianza de las alfa-amilasas, que por ejemplo, una German Altbier, donde vamos a buscar una atenuación salvaje, por lo que buscaremos un macerado “más fresquito”.
En el Radical Brewing, de Randy Mosher, por ejemplo, se dice que las alfa-amilasas trabajan en rango óptimo entre 65,5 y 71 °C, mientras que las beta-amilasas, entre 60 y 65,5 °C. Randy aconseja trabajar a 65,5 °C y mantenerlo una hora para conseguir un mosto que se convertirá en una cerveza maravillosa. Lo cual no es mal consejo (nunca puede ser malo viniendo de Randy) porque según su información, a esa temperatura actuarán tanto las alfa como las beta amilasas y nadie quisiera ser un almidón viviendo en ese empaste… John Palmer en el How to Brew [¡plink!]dice que la alfa amilasa trabaja mejor entre 67,7 y 72,2 °C, y que la beta amilasa entre 55 y 65,5 °C (siendo 67,7 °C la temperatura a la que deja de actuar).
En BeerSmithTM podemos ver [¡plink!] que recomiendan un rango total de entre 63 y 69 °C, concretando luego que el 68 – 75 °C es para la alfa amilasa, y 54-65 °C para la beta amilasa. En este artículo de Dave Green publicado en la revista Brew Your Own en 2008 [¡plink!] y titulado “The Science of Step Mashing” se dice que la beta-amilasa trabaja en rango óptimo entre 54-66 °C (con especial énfasis a los 64 °C, y quedando inactiva a los 71 °C. Respecto a la alfa-amilasa, se dice que su rango ideal sería el de 66-71 °C (mejor a 70 °C) y que a partir de 77 °C deja de trabajar.
Un último ejemplo, en el libro Brewing de Michael J. Lewis y Tom W. Young apuntan que la alfa amilasa trabaja a 70 °C (e incluso a “temperaturas más altas”) mientras que la beta amilasa trabaja en un rango de entre 55 y 60 °C, para acabar añadiendo que la alfa amilasa trabaja entre 10 y 15 °C más alto que la alfa amilasa.
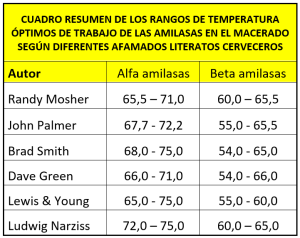
Podríamos seguir poniendo ejemplos de diferentes publicaciones especializadas, pero visto lo visto, mirando el cuadro resumen, tenemos suficiente información y contrastes para trabajar. Como se dice continuamente en todos los artículos del blog, lo mejor es la experimentación y la experiencia propia. Coge estos datos y aplícalos a tus elaboraciones diarias, evalúa los resultados, cambia algo para ver cómo afecta y aprende del resultado.
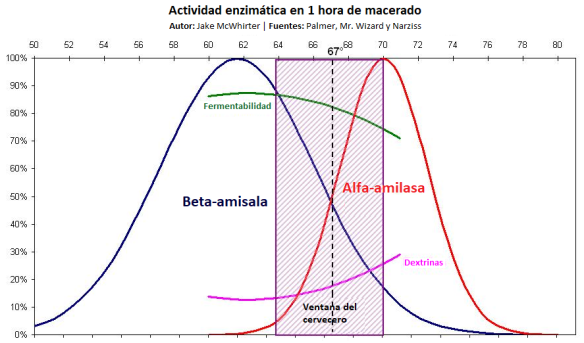
Como colofón, en este curioso post [¡plink!] Se habla de un concepto muy bonito. Su autor, Jake McWhirter (quien ha tenido la amabilidad de dejarme usarlo aquí), ha desarrollado la “ventana del cervecero”, un espacio dentro de un gráfico donde se ve la actividad de la alfa-amilasa en porcentaje, con su curva en base a la temperatura, y que reproducimos aquí por su valor visual. Un cuadro parecido, pero menos visual, con el mismo concepto, se encuentra en la página 241 del libro Brewing (segunda edición) de Michael J. Lewis and Tom W. Young, pero preferimos reproducir el de Jake.
Los jombrigüeres aplicados pueden leerse este estudio de la Brewing Research Foundation, titulado “The effects of mashing temperature and mash thickness on wort carbohydrate composition”, donde hay interesantes cuadros de la actividad de las amilasas [¡plink!].
Cuadrando la temperatura de macerado (La “fluctuosidad” del asunto)
En la práctica, para conseguir una temperatura concreta, hay que llenar el macerador con el volumen de agua que queremos (de acuerdo con un empaste objetivo, del que hablaremos más abajo) y luego añadir el grano al agua. Como el agua va a perder grados por el camino, primero al entrar en contacto con el macerador, y luego, al enfriarse un poco más por culpa del grano, lo suyo es calcular la temperatura inicial del agua, previendo que bajará al punto que tú quieres cuando la mezcla se complete y la temperatura se homogenice. Si repites la misma receta una y otra vez, no te hará falta hacer los cálculos siempre que elabores, ya que los factores más importantes son la temperatura objetivo, la relación agua:grano (empaste) y la temperatura del grano. Las calculadoras de internet, como por ejemplo la que hay en la ACCE [¡plink!] ayuda mucho. Casi siempre este tipo de calculadoras te darán la pista definitiva para saber a qué temperatura poner el agua. Además, ya sabemos que no hay volverse loco tratando de ajustarlo todo a la décima de Celsius.
De vez en cuando, te encontrarás con algún problema, y el cálculo no ha funcionado del todo bien, así que conviene tener un plan alternativo para ajustar de manera rápida la temperatura del macerado, y seguir adelante con el plan preconcebido del perfil de la receta.
La manera más sencilla es añadir una pequeña cantidad de agua, ya sea fría o caliente, para acabar de clavar la temperatura deseada. La calculadora de la ACCE tiene un apartado para añadir agua caliente si queremos subir la temperatura (diseñada para escalones) [¡plink!] o en Brewer’s Friend tienes una que sirve para subir y bajar la temperatura [¡plink!]. Aunque me parece poco práctica porque para enfriar te hace el cálculo con la temperatura a 10 °C, algo demasiado arbitrario. En realidad, hay mil calculadoras que puedes usar, como la Jim’s Beer Kit [¡plink!].
Lo que hace todo el mundo es añadir agua poco a poco hasta conseguir bajar la temperatura al rango deseado. Si la temperatura a ajustar es poca, también te valdrá si remueves el empaste durante un rato hasta llegar al punto requerido. En equipos más trabajados (RIMS/HERMS), subir la temperatura del macerado conlleva un sencillo recirculado aplicando calor.
En cuanto a qué temperatura elegir macerar, o bien, si elegir varias temperaturas durante un mismo macerado, a más de uno se le ha ocurrido el siguiente planteamiento: si primero macero a una temperatura muy alta, activando las alfa-amilasas, tendré un mosto lleno de cachitos de azúcares, pero un poco grandes (alias “dextrinas”). Si en ese punto, bajo la temperatura, saldrán a correr las beta-amilasas y liquidarán todos esos azúcares en una kermesse enzimática… Y el resultado será un mosto super-fermentable y atenuante… ¡Pues no! Si lo hacemos así, las altas temperaturas que favorecen a las alfa-amilasas desnaturalizarán a las beta-amilasas, que perderán su función biológica, convirtiéndose en enzimas no-muertas que no harán nada para que tu mosto sea más fermentable.
Este planteamiento, que es inútil en una infusión simple, funciona en los macerados por decocción, ya que solo una parte del mosto se lleva a ebullición. Pero de la decocción ya hablaremos en otro artículo. Aquí hemos venido a hablar de la infusión.
Experimento en Brülosophy (Alta temperatura VS. Baja temperatura)
En uno de sus famosos “exbirramentos” de uno de mis blogs de referencia como es Brülosophy, experimentan con la misma receta, pero cambiando la temperatura de macerado. Parten de la base de que la beta-amilasa trabaja en el rango de 55-65 °C y la alfa-amilasa, en el de 68-72 °C, y van a hacer un macerado a 64 °C y a 72 °C. Para resumir el experimento, del que podéis encontrar todos los detalles en el blog original [¡plink!], podemos decir que han usado un kit preparado (Biermuncher’s Centennial Blonde Ale), y ambos macerados han resultado en mostos con una densidad inicial de 1,040, para acabar en una densidad final de 1,005 para el macerado a baja temperatura y de 1,014 en el de alta temperatura. La diferencia de 9 puntos de densidad ya nos constata de forma fiable que van a ser cervezas diferentes, pero el aspecto final de la cerveza también cambia: la espuma es más estable en la macerada a baja temperatura y también la cerveza era más cristalina de forma notable.
Tras la tradicional cata de las muestras, aunque a priori todo iba a indicar que se iba a identificar de manera fácil la diferencia de cuerpo, alcohol (4,4% vs. 3,4%) y el dulzor de la malta entre una y otra, los que notaban la diferencia fueron muy pocos. Es más, cuando se les explicó el experimento a los catadores y se les pidió que identificaran la muestra macerada a mayor temperatura, sólo 4 de 9 supieron señalarla. Lo que parecía muy evidente, al final no lo es tanto.
Como casi todas las veces, parece que “nada de lo que hagas importa”, para los consumidores finales, pero ya hemos visto cómo afecta a los números y a los de morro fino. A partir de aquí, la cerveza y las decisiones, son de cada uno.
Hay un segundo experimento con dos macerados, a 65 y 67 °C [¡plink!]. En cuanto a densidades iniciales, fueron 1,059 para la del macerado a 65 °C contra 1,058 para la de 67 °C (bastante poco indicativo). Las densidades finales también varían, aunque muy poco: 1,008 para la de 65 °C contra 1,009 a 67 °C. El autor del experimento declara no encontrar diferencias entre cuerpo, retención de espuma, espuma generada o cualquier otra característica específica típicamente atribuida a los macerados en rango alto (67 °C no es que sea muy alto). El autor reconoce que pasa una de cada tres pruebas triangulares para identificar la muestra diferente en una cata. Lo que nos viene a decir en este experimento es que no hay apenas diferencia entre macerados de 2 °C de diferencia (al menos, en ese rango de 65-67 °C), lo que nos tranquilizará a la hora de tomar las medidas de temperaturas.
Tanto en el primer experimento que hemos visto como en el segundo, los resultados son un poco descorazonadores, en cuanto a obtener cervezas diferentes. En realidad, mucha culpa de esto lo tienen las maltas bien modificadas, que hacen el trabajo muy fácil para los macerados. Si realmente quieres aumentar el cuerpo de tu cerveza de una manera fiable, conviene añadir maltas que aporten azúcares no fermentables, como las maltas Crystal y Caramelo, que además te van a favorecer la retención de espuma (los supertacañones cerveceros aconsejan un rango de entre un 2 y un 15% del total del grano de la receta, dependiendo del estilo). Otras maltas, como la Special B o incluso las oscuras como la Chocolate o la cebada tostada, también aportan azúcares no fermentables.
Temperatura final (lavado)
Cuando damos el macerado por terminado, el primer paso es subir la temperatura del mismo, habitualmente por encima de los 74 °C (otras fuentes recomiendan 77-78 °C). El paso final del macerado se suele conocer como “lavado”, donde hacemos correr el mosto a través de la cama de grano con la gracia de arrastrar todos los azúcares posibles.
¿Qué conseguimos con este paso? Pues algo realmente importante, que, aunque parezca banal al principio, es bastante sustancial cuando lo entiendes. Si dejas el mosto a su suerte en este punto, las enzimas van a seguir actuando, con más o con menos efectividad, pero podrán variar las cualidades de tu mosto, por ejemplo, las beta-amilasas pueden seguir acuchillando de manera despistada y vaga ciertas dextrinas y aumentar la fermentabilidad, y con ello, bajar el cuerpo de la cerveza, cuando tú precisamente lo que querías es una cerveza con mayor cuerpo.
Si subes la temperatura conseguirás que las enzimas queden inactivas, lo que fijará, de algún modo, la proporción azúcares fermentables y no fermentables que has estado trabajando todo este tiempo. Además, de manera colateral, conseguirás gelatinizar algún almidón residual, lo que te va a permitir un mejor flujo del mosto, algo importante a la hora de vaciar el macerador a través de la cama de grano.
Tercera palanca | El pH
Al igual que hemos visto con las temperaturas, existe otro baile de rangos de pH dependiendo de la publicación que consultes. Lo que hay que tener claro es que nuestras enzimas favoritas van a trabajar bien dependiendo de si el pH es el indicado o no. De nada servirá dejarlas en su rango de temperatura si luego el pH del macerado no está acorde con lo que necesita la enzima concreta, ya que la conversión de los almidones será más costosa (y lenta).
Habitualmente, se suele recomendar un rango de pH para el macerado de entre 5,2 y 5,6 o incluso se acota a 5,3 – 5,6 (medidas tomadas a “temperatura de habitación”, 25 °C).
Pero el baile de cifras da comienzo: Por ejemplo, en el New Brewing Lager Beer, Gregory J. Noonan apunta que el pH idóneo para la alfa amilasa es de 5,1 a 5,9 aunque recomienda un rango de 5,2 a 5,5 para el macerado completo. Ludwig Narziss apuesta por el 5,5 a 5,6… Palmer dice que un rango de 5,4 – 5,8 es lo mejor para el macerado. Un lío.
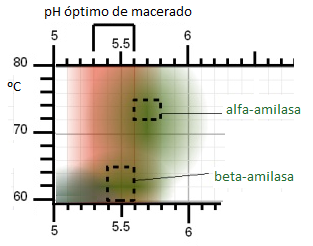
Además, según el gráfico aportado por Braukaiser [¡plink!] se sabe que la beta amilasa es favorecida por un pH de 5,4 – 5,5 y que a la alfa amilasa le favorece más un 5,6 – 5,8. Pero si observamos bien dicho gráfico, la intensidad del color verde nos proporciona información extra: la enzima trabaja más activa en los colores más intensos, pero vemos que el rango de pH se estira a otros colores más tenues, donde podemos acomodarnos con un pH para todo el macerado.
Con esta información podemos favorecer el trabajo de la alfa amilasa o de la beta amilasa a conveniencia, según el estilo de cerveza que vayamos a hacer.
Aparte de eso, ya dijimos, vía Thean Krueger [¡plink!] que un pH de 5,2 – 5,4 durante el macerado conviene a cervezas claras, mientras que las oscuras (Brown Ales, Stouts…) se favorecen de un rango más alto, 5,6 – 5,8.
Ya vimos en el post acerca de los mitos más extendidos entre los hombrigüeres [¡plink!] que durante mucho tiempo se creyó que una alta temperatura en el lavado podría arrastrar compuestos (taninos) que iban a provocar cierta astringencia en el mosto. Los últimos estudios, tal y como vimos en el post, delatan que la astringencia se debe a un pH por encima de 6.0.
Por datos como estos, conviene no tomarse el tema del pH a la ligera. No obstante, le dedicaremos un post entero más adelante, para un mejor entendimiento de todo lo que conlleva. Es más, no solo el pH es vital para un buen macerado, si no que la composición del agua también es clave. Por ejemplo, cierto contenido en calcio es esencial, puesto que las amilasas (alfa y beta) son dependientes del calcio, y en su ausencia, no pueden trabajar.
Cómo ajustar el pH del macerado
Aunque este artículo no va de tratamiento de aguas, si no incluía algunas palabras para ayudar al jombrigüer con el pH, sentía como si lo dejara un poco incompleto. Dicho lo cual, no pretendo ahondar mucho en el tema, pero sí vamos a dar algunas indicaciones acerca de cómo manipular el pH para usar bien “la palanca” del pH.
Los métodos para ajustar el pH son variados, aunque casi siempre se recurre a la adición de algún ácido (fosfórico, cítrico o láctico la mayoría de las veces), o mediante cambalaches como la malta acidificada, o incluso con algún producto específico que te soluciona los problemas.
Lo principal es tener un medidor de pH (pH-metro o pehachímetro si eres un rebelde semántico) que te ayude en este paso, bien calibrado. Lo segundo, también importante, sería conocer, aunque sea de manera aproximada, tu agua.
No obstante, como regla general, podemos decir que las cervezas oscuras suelen necesitar menos tratamiento (en cuanto al pH) que las cervezas claras, ya que las maltas tostadas van a producir el efecto colateral de bajar el pH.
Como apunte, el pH del macerado rara vez bajará del 5,2 de manera natural. Sin embargo, sí que puede (de manera natural), ser más alto que los valores recomendados, y en ese caso tocaría actuar para mejorar los resultados.
A continuación, veremos de forma resumida algunos métodos para bajar el valor del pH de tu macerado.
- Ácido láctico: es un ácido orgánico producido por bacterias (como el lactobacillus). Es bastante accesible y se encuentra barato en muchas tiendas de insumos cerveceros. [¡plink!]. Se suele encontrar líquido, disuelto al 80% – 88%. Conviene leer las indicaciones del fabricante respecto a su utilización y dada la pequeña cantidad que se usa para ajustar el pH, no deja rastros de sabor en la cerveza.
- Malta ácida (o acidificada): una malta con un poco de historia. Si tenemos en cuenta el cuento mercadotécnico-alemán de la afamada, romántica e inútil Ley de la Pureza [¡plink!], los cerveceros alemanes no podían usar compuestos como ácidos para bajar el pH. Estaban en clara desventaja con otros cerveceros de fuera de Alemania, por lo cual, hecha la ley, hecha la trampa. Desarrollaron una malta acidificada (malta Pilsen de toda la vida, a la cual echaban ácido láctico), la cual, al incluirla en los macerados en los que se necesitaba bajar el pH, actuaba a la perfección y cumpliendo con la “Ley de Pureza” o “Reinheitsgebot”.
- Ácido fosfórico: Es tan accesible como el ácido láctico en muchos distribuidores de insumos cerveceros. Es un ácido inorgánico, muy común en la fabricación de refrescos y otras industrias alimentarias. No hay impacto en el sabor, cuando las cantidades usadas son coherentes. De hecho, el umbral de percepción del sabor del ácido fosfórico es más alto que el del ácido láctico (es decir, se detectaría antes el lactato que el fosfórico a una cantidad idéntica de ppm).
- Estabilizadores de pH: Hay productos en el mercado que sirven para facilitarle la vida al jombrigüer, como el 52 pH StabilizerTM de Five Star [¡plink!]. Usando aproximadamente 8 gramos por cada 10 litros de agua, te controla de manera despreocupada el pH del macerado, reduciéndolo a 5,2 y dejándote tiempo para dedicarte a otras cosas. Aunque esta solución parezca mágica, puede que no sea oro todo lo que reluce. Es evidente que al igual que no hay una pastilla milagrosa que cure todas las enfermedades, es lógico pensar que cada agua es un mundo y pueda no servir para todas las aguas. De hecho, en la «Guía Completa de Defectos en la Cerveza» de Thomas Barnes hay un apartado dedicado al descriptor de sabor «5.2», ya que todo indica a que con aguas muy duras (o si se te va la mano), puede influenciar en el sabor. Las malas lenguas apuntan a que este estabilizador se desarrolló para una cervecera en concreto, pero luego comercializado por petición popular. Por tanto, las aguas que se alejen del perfil original no se verán muy beneficiadas.
- Incluso, como truco, se podría hacer un escalón de temperatura que favorezca la acidificación del macerado. Conocido en inglés como “acid rest” y mal traducido de manera sistemática como “descanso ácido”, consiste en remojar la malta entre 30 y 52 °C durante unos 20 minutos, de manera habitual. Como va a depender del agua, lo más coherente es hacer el remojado de la malta al rango de temperatura e ir tomando las mediciones del pH cada cierto tiempo para asegurarse el valor adecuado. Este método ya es obsoleto, por incómodo (hay veces que este paso ha empleado horas).
La mayoría de las veces, lo normal es que tu suministro de agua se mantenga estable, por lo que cuando tengas varios perfiles conocidos, simplemente será repetir los ajustes de manera sistemática. No obstante, de vez en cuando los valores del agua, incluso el pH, varían por alguna razón. No viene mal hacer mediciones periódicas del agua, y si tu lote va a ser de un volumen considerable, conviene no fastidiarlo por algo como un pH inadecuado en el macerado.
Cuarta palanca | El empaste
Llamamos empaste a la relación agua/grano de la mezcla en el macerador, también conocido como “disolución”, pero como es menos glamuroso lo seguiremos llamando empaste. Muchas veces se tiene poco en cuenta, pero es necesario saber que empastes más espesos (de 1,7 a 2,6 litros de agua por cada kilo de grano), provocará que las enzimas tengan más movilidad, y actúen más rápido. Sin embargo, tienen una vida más corta. En general, los empastes más espesos son más fermentables.
Empastes más ligeros o aguados (más de 3 litros de agua por cada kilo de grano), provocará que la actividad de las enzimas sea más lenta, por lo que el mosto resultante será menos fermentable, aunque si se alarga el tiempo, podemos compensar ese punto. También favorece que haya más contenido de nitrógeno soluble en el mosto.
En este interesante artículo de Tom Flores, de 1999 [¡plink!] se afirma, entre otras cosas, que a nivel profesional el macerado se pilota en rangos de entre 2 y 4 litros de agua por grano, y más específicamente, entre 2,5 a 3,2.
Y en una animada conversación con el compañero bloguero, filósofo y orador de Birrocracia [¡plink!] durante la redacción de este post, hablamos acerca de que la clave está en la dispersión. Esto es, en un empaste muy líquido las enzimas tienden a estar más dispersas y actúan en el almidón con mayor dificultad. Como ejemplo para entenderlo, puedes pensar en 2 pilas de cien platos cada uno, la primera la lavas con una cierta cantidad de agua y una cierta cantidad de jabón. La segunda, sin embargo, la lavas con la misma cantidad de jabón, pero con el doble de agua. En el segundo caso lavarás mejor, porque la concentración de jabón será más pequeña. Además, está el hecho de que cuando hacemos macerados con maltas oscuras, convienen macerados más densos y lavados más intensos (no bajará el pH), mientras que las birras claras… convienen macerados más líquidos, pero lavar con menos agua.
Como comentario final para conocer este punto de manera más clara, podemos acudir de nuevo a Brülosophy y ver qué pasa cuando haces la misma receta con un empaste de 2,5:1 y otro de 5:1 [¡plink!]. En este caso, al elaborar una Southern Summer Pale Ale, el macerado con empaste estándar (el de 2,5:1) empezó en una densidad inicial de 1,052 y acabó en 1,010, mientras que el macerado más diluido (5:1) empezó en 1,051 y acabó en 1,012. En la cata de las cervezas, sólo 5 de los 24 catadores supieron identificar la muestra que sabía diferente. Por tanto, una vez más, Brülosophy nos dice, al menos para ese estilo de cerveza, que salvo por un 0,4% de alcohol, las cervezas resultantes eran idénticas.
Si vas a aplicar calor directamente al macerado para controlar la temperatura, debes huir de empastes espesos, para evitar quemar el grano.
Quizá, para aprovechar el empaste, visto lo visto, habría que jugar un poco más con las temperaturas y el tiempo, en lugar de mantener un macerado por infusión simple mono-temperatura. O también, empezar a pensar que la teoría y la práctica discurren por sendas paralelas que no se tocan ni en el más oscuro de los infinitos.
Consideraciones finales
Muchas veces, además, al conocer cómo funcionan estas “palancas”, puedes compensar algún error o deficiencia en alguno de los parámetros por medio del ajuste de otro. Pongamos que tienes un pH de macerado de 5.7 pero no puedes manipularlo. Como sabes que las enzimas trabajarán más lentas, puedes alargar el macerado, o hacerlo más espeso, para que las enzimas estén activas más tiempo. O ambas cosas.
Existen otros parámetros que también influyen en el macerado, pero no he visto conveniente incluirlos en la categoría de “palancas”.
Por ejemplo, la molienda influirá en el macerado, pero no es algo que estimo que puedas manipular a placer para conseguir un efecto u otro. Hay una molienda efectiva, y una molienda mal hecha. Lo ideal es hacer la molienda de la malta de la manera óptima, y no perder tiempo ni dinero haciéndolo mal.
La planificación del macerado, con un escalado de temperaturas programado, evidentemente, tendrá impacto en el macerado, pero para eso ya tenemos las palancas de tiempo y temperatura, no haría falta otra palanca extra.
El poder diastásico de la malta, del que ya hablamos aquí [¡plink!] también influirá en el resultado del macerado, pero muchas veces ni lo conoceremos, por lo que al igual que la molienda, lo suyo es conseguir malta fresca de calidad, bien modificada, y jugar con los parámetros que están a nuestro alcance.
Y como último apunte (ya para “nota”), hay una corriente de cerveceros que tienen muy en cuenta la oxidación en caliente, o HSA (Hot Side Aeration) en inglés. Vendría a decir que la presencia de oxígeno en el macerado va a afectar negativamente al sabor de la malta, atenuando o cambiando el original, así que chapoteos varios o lanzar el mosto desde altura podría perjudicar el resultado de la cerveza. A pesar de que Denny Conn lo desmiente en el artículo de los mitos más extendidos entre los jombrigüeres [¡plink!], si el tema te interesa puedes leer la traducción de un estudio acerca de este tema en el blog de Homebrewer.es [¡plink!], que te hará replantearte (o no) todo lo aprendido sobre la dichosa oxidación.
Conclusión
En definitiva, si estás empezando a hacer cerveza en casa, procura dirigir tus esfuerzos para conseguir un macerado entre 65 y 67 °C. Muchas veces, incluso 68 °C vendrán bien si tu macerador tiende a perder mucha temperatura (por ejemplo, si haces un macerado en BIAB donde la olla está poco aislada). Y poco a poco, jugar con 3 o 4 grados menos cada vez que elabores un nuevo lote. Así tendrás pruebas de contraste y conocerás los efectos de los cambios de temperatura. El resto de palancas y ajustes, vendrán con el tiempo.
Si ya llevas varios lotes a cuestas y tienes el alma inquieta, esta información te servirá para manejarte en tus siguientes recetas. No hay que dejar de experimentar, ni de aprender.
Prueba del yodo
Como hemos indicado en el apartado dedicado al tiempo, el método para saber si la sacarificación se ha completado o merece la pena emplear más tiempo en este proceso, se llama “prueba del yodo”, por la sencilla razón de que se emplea yodo para que éste reaccione con el mosto.
Es una prueba muy, muy sencilla. Consiste en coger muestras del macerado, evitando a toda costa los restos del grano. Los granos contendrán almidón de forma irremediable y te falsearán las pruebas. Cuando el yodo entre en contacto con el mosto, cambiará de color. Si cambia a colores amarillentos, ambarinos o tonos marrones, la conversión del almidón ha sido completa y puedes dar el macerado por acabado.
Si el yodo se vuelve azul oscuro, púrpura o negro, todavía hay almidones que convertir, y la mejor idea es dejar a tus amigas las enzimas trabajar durante un cuarto de hora más antes de repetir el test. Comprueba, además, la temperatura, no sea que esté en un rango equivocado y las enzimas no estén trabajando. Como siempre, macerado tras macerado, conocerás por la práctica cuánto tardas en completar la conversión de almidones y la prueba del yodo será un vago recuerdo de tu infancia cervecera.
Otro truco de “viejo cervecero” es extraer un poco de mosto y observarlo a la luz. Si el mosto es claro (sin turbidez), estaría en un buen punto de pasar al siguiente paso. Si el mosto presenta turbidez, es preferible aguantarlo más tiempo para conseguir una mejor clarificación.
Referencias:
- Mashing Basics (Marc Sedam, Zymurgy March/April 2002)
- Teoría de la Maceración (Pablo Gigliarelli, Revista MASH 2004) [¡plink!]
- The Theory of Mashing (com) [¡plink!]
- Brewer’s Window: What Temperature Should I Mash at? [¡plink!]
- New Brewing Lager Beer (Gregory J. Noonan)
- Homebrew Manual: A simple, ilustrated introduction to single infusión mash temperatures [¡plink!]
- “The Science of Step Mashing” (Dave Green, Revisa Brew Your Own, 2008) [¡plink!]
- “Brewing” (Michael J. Lewis y Tom W. Young)
- Managing Mash Thickness (Tom Flores, BYO, febrero 1999) [¡plink!]
- Mashing Variables: Techniques (Chris Colby, BYO, mayo/junio 2006) [¡plink!]
- Wizard; What mash temperaturas create a sweet or dry beer? [¡plink!]
- The Brewer’s Companion (Randy Mosher)