
En mi lento ritmo de creación de artículos, me he dado cuenta que para seguir el hilo de algunos de ellos, primero conviene tener claros algunos conceptos básicos. Como este blog está concebido a largo plazo, quiero pensar que dentro de algunos años el contenido del mismo sea el suficiente como para poder trabajar con él con independencia de otros recursos, al menos a ciertos niveles, mientras que dicha información sea a la par manejable, útil, práctica y entretenida.
Justo por esto, no me queda más remedio que centrarme también, de vez en cuando, en tribulaciones básicas de cervecero casero a las que poder hacer referencia en artículos venideros, sin tener que recurrir a otros sitios. Así que el post de hoy está dedicado a los Puntos de Densidad.
Cuando se empieza en el apasionante mundo del jombrugüin, dejando de lado los aburridos e insulsos kits de extractos y lanzándonos al jombrugüin en estado puro: el conocido como todo-grano (o 100% malta) todo son dudas, inseguridades y vacilaciones.
Por un lado tenemos nuestra agua, nuestro saco de malta de cebada, nuestros lúpulos perfectamente conservados y la levadura a punto para hacer nuestra primera elaboración. Hemos buscado unas cuantas recetas que elaborar, y como no queremos complicarnos demasiado hemos escogido una muy sencillita, pero no estamos seguros de si las cantidades de malta y de agua (¡o de lúpulos!) son las idóneas. Podemos imaginarnos al neojombrigüer moviendo cacharros de aquí para allá sin saber muy bien cómo actuar en cada momento (yo me sentía así), y pesando cantidades esperando no meter demasiado la pata… Así que una de las primeras preguntas que vienen a la mente es la de ¿cuánta malta tengo que poner aquí para llegar a la densidad que me marca la receta?
Parece simple, y en realidad lo es si somos capaces de manejar ciertos factores muy básicos. Es decir, si por un lado sabemos que necesitamos llegar a una densidad objetivo de 1,045 después de hervido y hemos calculado que la cantidad de mosto que vamos a tener en nuestro fermentador (una vez terminado el macerado y el hervido) es de 20 litros… ¿cuántos kilos de malta necesitamos poner en el macerador para que la densidad después del hervido no sea ni 1,060 ni 1,030… si no los 1,045 que hemos proyectado?
Hay mucho software (gratuito o no) que te hace estos tipos de cálculos sin ningún esfuerzo. Sin embargo, la gente curiosa (como yo) necesita saber de dónde vienen y a dónde van estos números. Yo quise saberlo al principio, con el ánimo de tener un mejor control de los procesos, y a la postre no he usado nunca ningún software de elaboración para hacer estos cálculos. Reconozco que tengo mi propia hoja Excel que he generado para no perder tiempo haciendo muchos cálculos manualmente, pero nunca he sentido la necesidad de apoyarme en un software específico para diseñar mis recetas.
La principal fuente de toda la información del post viene del libro de Ray Daniels, “Designing Great Beers”, pero hay multitud de otros sitios de referencia donde investigar los mismos parámetros, no se trata de ningún secreto ancestral, sino de lo primero que se aprende cuando se empieza a hacer cerveza en casa. Uno de mis post favoritos respecto a este tema (en inglés) es este [¡plink!] de la web http://homebrewmanual.com/ Además, la mayoría de las publicaciones se mueven en onzas, libras y galones y la suerte de este artículo es que ya habla en litros y kilos.
Y como el movimiento se demuestra andando, lo mejor es conducir la explicación a través de un ejemplo sencillo. Imaginemos que queremos hacer una cerveza de fácil elaboración, tipo English Pale Ale (Bitter, grupo 8B de la BJCP), con una densidad inicial objetivo de 1,045 y compuesta de los siguientes ingredientes:
92% Malta Pale
5% Malta Crystal
3% Copos de trigo
Así que para empezar a recabar la información necesaria para nuestra ecuación en realidad hay que irse al final del proceso: ¿cuánta cerveza quedará al final de todo el proceso? Este será el dato elemental que va a condicionar todo. Obviamente no será lo mismo hacer 10 litros de cerveza, que 20 o que 30. Así que en nuestro ejemplo vamos a suponer que queremos acabar con 25 litros de cerveza.
Llegados a este punto, ya podemos empezar a jugar con los Puntos de Densidad. En inglés unas veces se llaman Gravity Units y otras Gravity Points, con sus respectivas abreviaturas (GU y GP), pero nosotros simplemente les llamaremos Puntos de Densidad (PD). Además, los números calculados a la manera anglosajona (en libras y galones) no se corresponden con estos Puntos de Densidad a la española, puesto que al multiplicar cantidades dan resultados más pequeños que no podemos tener en cuenta.
Los Puntos de Densidad van a indicar de manera directa y segura la cantidad real de azúcares que hay en tu cerveza o en tu mosto (o la cantidad que quieres que haya). La densidad por sí misma es un valor que te indica un objetivo, pero si no está vinculado a un volumen concreto de cerveza, no es plenamente indicativo. Además, si te paras a medir densidades todo el rato, tendrás multitud de valores confusos y diferentes: una densidad en el primer mosto del macerado, una densidad en el segundo mosto, una densidad distinta antes de hervir, otra después de hervir… Sin embargo, los Puntos de Densidad sugieren un valor absoluto que te van a servir no sólo para saber que todo va bien, sino también para predecir qué va a ocurrir en el futuro inmediato (es más fiable que leer el futuro lanzando conchitas chiquititas sobre un tapete de felpa).
El principio del mismo es bien sencillo: el contenido de azúcar de un mosto, después del macerado, no varía. Supongamos que tenemos 10 litros de mosto, y le añadimos 5 litros de agua; es evidente que el total de azúcares del mosto no habrá variado con dicha adición de agua, solo que estarán más diluidos. En el caso contrario, si hervimos esos 10 litros de mosto y lo dejamos en 8 (por evaporación), tendremos exactamente la misma cantidad de azúcares, pero más concentrados (lo que equivale a un mayor valor de densidad). Pero en los tres casos, con 8, 10 o 15 litros, el contenido en azúcares es exactamente el mismo.
Si queremos explicarlo de manera más básica aún, tenemos la parábola de los gatitos en la piscina. Imagina una piscina hinchable llena de agua hasta la mitad donde están nadando siete tiernos gatitos. Imagina también que la piscina hinchable es tu olla, el agua es el mosto y los gatitos, los azúcares de la malta. Si llenaras la piscina de agua hasta arriba, seguirían siendo siete los gatitos que hay en la piscina. Y si abrieras el grifo para sacar el agua de la piscina, seguiría habiendo siete gatitos en la piscina. Varíe lo que varíe la cantidad de agua, los gatitos son los mismos. Varíe lo que varíe el volumen del mosto, una vez acabado el macerado y los azúcares están disueltos, dicho contenido en azúcares será constante a lo largo de todo el proceso.
Por tanto, podemos decir que:
Puntos de Densidad = Factor Denso x Volumen (litros)
¿Qué demonios es el Factor Denso? La respuesta rápida es que el Factor Denso es un nombre estúpido que me he inventado para darle un poco de lógica y coherencia a los cálculos. Resulta que para medir la densidad específica de un líquido se toma como referencia la densidad del agua destilada, que es 1. Si al agua pura se le van añadiendo y disolviendo otras partículas, la densidad aumenta… así, cuanto más contenido de azúcar hay en un líquido (en nuestro caso, el mosto), más alta será la densidad específica de dicho líquido. El problema viene que unas veces el valor 1 se expresa como 1.000 o como 1,000 o como 1000. En el caso de 1.000 es porque los anglosajones usan el punto para separar la parte decimal, igual que aquí usamos la coma. Esto provoca que muchas veces leemos la cantidad 1.080 o 1,080 como “mil ochenta” o “uno como ochenta”. Ni que decir tiene que las veces que no vemos ni coma ni punto (1080), decimos “mil ochenta” o, directamente, “ochenta”. A efectos prácticos nos da lo mismo, y puedes ver las cantidades con comas, puntos o solo números indistintamente en cualquier texto de cervecería casera. Sin embargo, a la hora de confeccionar una norma o fórmula matemática para cualquier aplicación informática, no es lo mismo.
El “Factor Denso” (fd) es la parte de la cifra de la densidad específica que está después del punto, o de la coma. Si tratamos la densidad como un valor de “mil y pico”, la fórmula sería (usando una densidad de 1.085 como ejemplo):
Factor Denso = 1.085 – 1.000 = 85
Si lo tratamos como una “coma”, la fórmula sería esta:
Factor Denso = (1,085 – 1) x 1.000 = 85
Pero no te hace falta hacer ningún cálculo matemático para saber que el Factor Denso de 1,085 es 85, o el Factor Denso de 1,060 es 60.
Así que si retornamos a la fórmula anterior y a nuestro ejemplo, tenemos que:
Puntos de Densidad = Factor Denso x Volumen (litros)
Puntos de Densidad = 45 x 25 = 1.125
Donde 45 es el Factor Denso de nuestra densidad inicial objetivo (1,045) y 25, el volumen total de litros de cerveza que queremos tener al final del proceso. Y el producto de ambos valores, 1.125, nuestros Puntos de Densidad objetivos. Con esta información ya podemos hacer (y saber) muchas cosas.
El Extracto Potencial
Las cosas empiezan a complicarse un poquito a partir de ahora, peno no demasiado. Si ya sabemos nuestros Puntos de Densidad objetivo (de ahora en adelante, PD), necesitamos saber qué cantidad de azúcares nos va a aportar cada malta o adjunto que hay en nuestra receta. Es evidente que todas las maltas no tienen el mismo contenido de azúcares, así que tenemos que saber, o al menos estimar cuál es el potencial de extracto de cada una de las maltas que intervienen en la maceración.
Aquí tenemos que obviar el hecho de que cada malta es un mundo, no ya la misma clase de malta de dos malterías diferentes, sino la misma malta de un mismo fabricante de cosechas distintas, o el mismo saco de malta usado en diferentes momentos (según la conservación del mismo) y otros factores de control. Se supone que estamos diseñando una receta, y no haciendo el business plan para los próximos diez años de un holding de empresas.
Podemos definir, simplificando, que el Extracto Potencial de las maltas (y adjuntos) es el contenido en azúcares susceptible de disolverse en agua caliente y formar parte del mosto. Es fácil de entender si decimos que el azúcar blanco (sacarosa, de hecho) tiene un Extracto Potencial a todos los efectos del 100%. Es decir, como el azúcar blanco es 100% azúcar, contribuirá con un 100% de sus azúcares a la densidad del mosto. ¡Obvio! Así, constituye la referencia para el resto de ingredientes.
La malta, sin embargo, no es 100% azúcar. Tiene cáscaras (por decir algo que podemos ver con los ojos) y otros compuestos diferentes. Por eso las malterías someten sus maltas a un estudio de laboratorio para conocer al detalle todas las características importantes: humedad, proteínas, alfa-amilasas… y por supuesto, el Extracto Potencial. Como ejemplo podemos consultar un análisis típico completo de las maltas de BRIESS Malt & Ingredientes Co. aquí [¡plink!], donde por ejemplo podemos ver que la malta Pilsen tiene un 80,5% de Extracto Potencial, mientras que la CaraPils tiene un 75%. Y de un vistazo simple podemos ver que las maltas base típicamente rondan el 80%, mientras que las especiales más comunes van desde un 78% a un 75% o un poquito menos (72%) para las más tostadas, con menor contenido en azúcar soluble en el mosto.

Ray Daniels, en el quinto capítulo de su libro “Designing Great Beers” usa un enfoque distinto para los Extractos Potenciales, pero poco, porque en esencia parte del mismo sitio. Primero, construye una tabla de referencia para las maltas más comunes, puesto que estar investigando las maltas de cada fabricante, durante todas las cosechas, es un tarea aburrida y poco práctica (las variaciones son mínimas) y segundo, plantea el potencial de cada una de ellas haciendo la siguiente estimación: si 1 libra de cierta malta se macera en 1 galón (americano) de agua, ¿qué densidad conseguimos? Teniendo esa información, podemos saber de manera sencilla cuánta malta usar para alcanzar la densidad del mosto que queremos. En nuestro lenguaje de litros y kilos, la pregunta sería ¿qué densidad conseguimos si ponemos 453 gramos de cierta malta en 3,784 litros de agua?, lo que haría impracticable cualquier tipo de cálculo sencillo. Sin embargo, con un cálculo teórico sencillo podemos transformar esos datos y estimar qué densidad nos darían 100 gramos de malta en un litro de agua, lo que sí es más útil.
En la siguiente tabla podemos ver un resumen de estos cálculos, junto a la información que usa John Palmer en el How to Brew [¡plink!] y de la que más adelante hablaremos de cómo usarla. Si nos fijamos bien entre ambas columnas, podemos ver una correlación muy clara entre ellas, lo que certifica que la base es la misma.
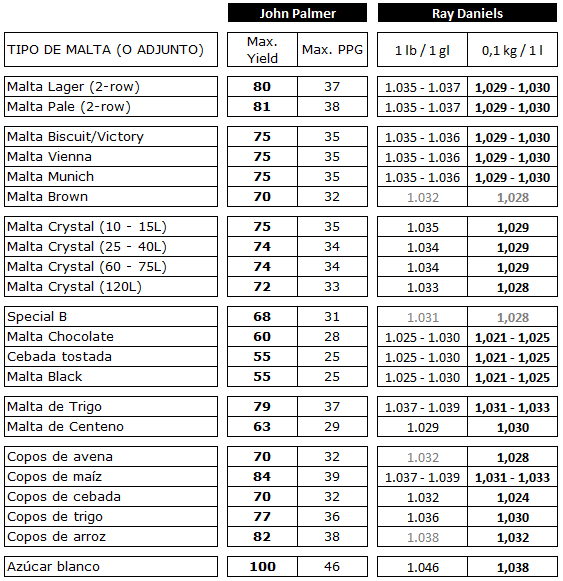
Por supuesto, tenemos que tener en cuenta que se trata de un cálculo teórico, porque en la mayoría de los casos, aún en las condiciones más favorables del mundo, no todo el Extracto Potencial de la malta pasa al mosto… y por eso tenemos que hablar del rendimiento del macerado.
El rendimiento del macerado
Podemos (y lo haremos) dedicar un post entero acerca del rendimiento del macerado, ya que hay corrientes de opinión, teorías contrarias y hasta extremismos religiosos acerca de cómo calcular de forma correcta el rendimiento del macerado. Y realmente es un tema apasionante sobre el que discutir.
No obstante, para el caso que nos ocupa es mejor pasar un poco de puntillas y centrarnos en otras prioridades. Quedémonos con el hecho de que la realidad es que no todas las cosas salen siempre como las planeamos, y aunque una malta tiene un potencial de extracto dado, hay muchas variables y acontecimientos que van a influir en el macerado para que todo ese extracto pase al mosto, y finalmente, en la mayoría de los casos sólo pase una parte del mismo. Por eso hablamos del fenómeno conocido como “rendimiento del macerado”. Según Ray Daniels, en los equipos usuales de jombrugüin dicho rendimiento suele moverse en el rango de un 65% en los casos más pobres y en un 80% en los mejores (insisto, esto es carne de debate que ya abordaremos en otro post, no vamos a discutirlo ahora) y la idea es que cada uno de nosotros sepamos el rendimiento de nuestro equipo.
Como al principio es difícil saberlo o si estás usando un equipo por primera vez es imposible saberlo, lo ideal es hacer una estimación al 70% o al 75%, y luego ir ajustando en función de los resultados. Es recomendable ser conservador con este dato y usar el 70% al principio, porque si alcanzas más rendimiento, siempre puedes añadir más agua y acabar con más cerveza.
Empezando los cálculos
Recopilemos los conceptos que hemos manejado hasta ahora: conocemos los Puntos de Densidad (PD), el Extracto Potencial (ExP) de las maltas y el Rendimiento del macerado (R%), así que con todo esto podemos obtener respuestas a nuestras preguntas iniciales.
Como hay diferentes planteamientos y enfoques, vamos a ver dos de ellos y que cada cual use el que más le convenga. Antes de usar estos cálculos para el ejemplo inicial de la receta propuesta, vamos a explicar las fórmulas como si sólo usáramos una única malta para alcanzar la densidad objetivo, así será fácil de entender. Digamos, entonces, que queremos alcanzar una densidad de 1,045 para 25 litros de cerveza usando sólo malta Pale.
El enfoque Daniels
Si estudiamos el planteamiento que Ray Daniels usa en su libro, y convertimos sus fórmulas a kilos y litros, obtendremos la siguiente fórmula simplificada:
Kg de malta= Puntos de Densidad / Extracto Potencial / Rendimiento / 10
( Kg = PD / ExP / R% / 10 )
Donde:
Kg de malta (Kg): el resultado de la fórmula nos dará directamente los kilos de malta a usar en el macerado.
Puntos de Densidad (PD): los puntos de densidad objetivo que hemos calculado para conseguir una densidad específica después del hervido. Recordemos que en nuestro ejemplo tenemos un objetivo de 1.125 PD (45 x 25 litros).
Extracto Potencial (ExP): es el extracto potencial de cada malta de la tabla de referencia que hay más arriba, expresado en modo “factor denso”, ya explicado. Según dicha tabla, la malta Pale tiene un extracto potencial de 1,030, lo que expresado como “factor denso” sería 30.
Rendimiento (R%): es el rendimiento del macerador, expresado en %. Si partimos de la base de un 70% para empezar, tendremos que usar 0,70.
Por tanto:
Kg de malta = 1125 / 30 / 0,70 / 10
Kg de malta = 5,357
Claro y sencillo. Pero… ¿qué pasa si no usamos sólo una malta, sino varias como en la receta planteada al principio? No es para nada complicado, en serio. Volvamos a ese ejemplo. Recordemos que la receta original era:
92% Malta Pale
5% Malta Crystal
3% Copos de trigo
Y como ya sabemos que nuestros Puntos de Densidad objetivo son 1.125, sólo hay que ponderar qué parte de material fermentable aportará cada uno de los ingredientes. Como tenemos los porcentajes a mano, no hay nada más sencillo:
Malta Pale: 1125 x 0,92 = 1035 PD
Malta Crystal: 1125 x 0,05 = 56 PD
Copos de trigo: 1125 x 0,03 = 34 PD
Hemos redondeado los decimales para no complicarnos la vida (no habrá diferencias). Ya sabemos que de los 1.125 PD, 1.035 PD vendrán de la malta Pale, 56 PD de la Crystal y 34 PD de los copos de trigo. Así que ahora aplicamos la fórmula que ya conocemos, teniendo en cuenta que según la tabla de referencia, el extracto potencial de la malta Crystal es 28,5 (como pone 1,028 – 1,029 tiramos por la media y con esto intento además transmitir que estamos estimando y que esto no es una ciencia exacta ni alquimia delicada) y el de los copos de trigo, 30.
Por tanto:
Kg de malta Pale: 1035 / 30 / 0,70 / 10 = 4,928 kg.
Kg de malta Crystal: 56 / 28,5 / 0,70 / 10 = 0,280 kg.
Kg de copos de trigo: 34 / 30 / 0,70 / 10 = 0,162 kg.
C’est fini. Ya tenemos nuestra receta completa.
El ‘otro’ enfoque
Como ya se ha comentado, hay muchos planteamientos para hacer los mismos cálculos, aunque casi todos nos vienen dados en libras y galones (o lo que es peor, en alemán). Como en esta página [¡plink!] los cálculos ya vienen en litros y kilos, creo que merece la pena echar un vistazo a ver qué dice.
El autor de esta web, un tal John, toma como referencia lo que a partir de ahora llamaremos el “Punto de Referencia del Azúcar”, o el dato de que la sacarosa tiene 46 PPG (Points per Pound per Gallon). Esto nos dice que por cada libra de azúcar que se añade a un galón de agua, obtenemos 46 puntos de azúcar. Esta información la podemos contrastar en la página de otro John, esta vez, John Palmer y su How to Brew [¡plink!]. Como esta información es poco práctica por sí sola, nuestro amigo la convierte en Puntos por Kilogramo por Litro (lo que empezaremos a llamar PKL), usando el factor de conversión de 8,345.
Por tanto:
PKL = PPG x 8,345
PKL = 46 x 8,345 = 383,87
Redondeando, podemos decir que es 384. Y esta cifra es importante, porque lo que en realidad te está diciendo es que, teóricamente, si añadiésemos 1 kilo de azúcar en 1 litro de agua, estaríamos añadiendo 384 Puntos de Densidad. Teniendo en cuenta esta información y lo aprendido hasta ahora respecto a rendimiento y Puntos de Densidad, podemos aplicar esta fórmula:
Kg de malta = Puntos de Densidad / (Extracto Potencial % x Rendimiento % x 384)
No estamos haciendo otra cosa que modificando el potencial del azúcar con respecto al potencial que tiene una malta concreta y al rendimiento del macerado, y enfrentándolo a los Puntos de Densidad que queremos conseguir. Veamos los ejemplos.
Igual que antes, empecemos suponiendo que vamos a usar sólo la malta Pale para llegar a los 1.125 PD. Aquí no usamos la tabla de Extracto Potencial desarrollada por Daniels (y convertida a kilos y litros por mí), sino la parte reservada a John Palmer y que podemos ver en su propia página [¡plink!], en la columna Max. Yield (Rendimiento Máximo). Si queremos comparar esta información, podemos fijarnos en la columna llamada “Extract FG%” en documentación de BRIESS que vimos al principio del artículo, y como se expresa en %, el 80 de la Malta Pale se convierte en 0,80. Respecto al Rendimiento, tomamos el mismo de referencia, un 70%, o sea, 0,70.
Por tanto:
Kg de malta = 1.125 / (0,80 x 0,70 x 384) = 5,232
La diferencia con el anterior planteamiento son apenas 125 gramos, así que podemos considerar que los dos apuntan al mismo sitio.
De igual modo que hemos hecho antes, si tenemos en cuenta la receta del ejemplo inicial y aplicamos la fórmula una vez ya ponderados los porcentajes a los 1.125 PD y cogiendo los potenciales de la malta Crystal y los copos de trigo de la tabla de John Palmer (74 y 77 respectivamente) tenemos que:
92% Malta Pale; 1125 x 0,92 = 1035 PD
5% Malta Crystal; 1125 x 0,05 = 56 PD
3% Copos de trigo; 1125 x 0,03 = 34 PD
Kg de malta Pale: 1035 / (0,80 x 0,70 x 384) = 4,813 kg.
Kg de malta Crystal: 56 / (0,74 x 0,70 x 384) = 0,282 kg.
Kg de copos de trigo 34 / (0,77 x 0,70 x 384) = 0,164 kg.
Si lo comparamos con el planteamiento anterior, vemos que las variaciones son mínimas y que ambas cantidades nos van a dar resultados similares.
Ahora ya sabemos lo suficiente como para poder calcular cualquier cantidad de malta necesaria para adaptar y elaborar cualquier receta que nos encontremos. En la tabla de maltas que existe en HomeBrewTalk.com [¡plink!] podemos obtener información de muchas otras maltas que no están listadas en la tabla-resumen de este artículo. Tampoco hay que perder la cabeza, si haces los cálculos con el valor potencial de una malta parecida o similar, no vas a notar mucha diferencia en la densidad, date cuenta que los porcentajes en peso de las maltas particulares (y por ende, los Puntos de Densidad que aportan) son pequeños.
Implicaciones prácticas
Los Puntos de Densidad no sólo sirven para diseñar recetas, sino para anticiparse a errores en la elaboración. Ya sabemos gracias a la parábola de los gatitos en la piscina hinchable que la cantidad de azúcares no cambia por mucho que reduzcas el mosto (hirviéndolo) o lo diluyas (añadiendo más agua).
Por tanto, supón que pones 35 litros de mosto en tu olla de hervido con una densidad de 1,041 y sabes que si hierves durante 90 minutos tu olla evapora 8 litros. O imagina que, directamente, quieres hervir hasta conseguir 27 litros, que es lo que cabe en tu fermentador. Cualquier posibilidad es válida, es por tener un ejemplo para poder explicar este punto.
Como los Puntos de Densidad serán los mismos con 35 litros y con 27, y sabemos que tenemos una densidad específica de 1,041 con 35 litros, podemos saber qué densidad vamos a tener con 27 litros, aplicando la siguiente fórmula:
PD al final del hervido = (Puntos de densidad al principio x Volumen al principio) / Volumen al final
Recuerda poner la densidad de acuerdo al modo de “factor denso” que ya hemos explicado. Por tanto, en el ejemplo:
PD al final del hervido = (41 x 35) / 27
PD al final del hervido = 1435 / 27
PD al final del hervido = 53,15
Esa cifra de 53,15 nos dice que al final del hervido tendremos una densidad de 1,053. Yo este cálculo lo he usado a veces cuando he medido la densidad antes de hervir y luego, con el jaleo de enfriar el mosto y limpiar todo, he puesto la levadura en el mosto olvidándome de medir la densidad.
Si cuando hagas esta estimación te das cuenta de que te has quedado corto con la densidad, puedes arreglarlo hirviendo más tiempo o bien añadiendo extracto seco (o azúcar). Si por el contrario la densidad prevista es más alta de la que esperabas, puedes añadir agua para rebajarla (o incluso, quitar mosto para usarlo para otros menesteres como hacer starters y sustituirlo por agua).
Ultimas reflexiones
En internet podemos encontrar miles… qué digo miles… ¡cientos de miles!… qué digo cientos de miles… ¡millones!, ¡millones de recetas de cervezas!, todas ellas diferentes y particulares entre sí. Sin embargo, ya hemos visto que la información básica para poder adaptar las recetas son las densidades objetivo, el volumen deseado y el rendimiento del macerador (entre otras).
En la mayoría de los casos, en estas recetas que están en la web, se omite el rendimiento del macerador, pero sin embargo se dan pesos concretos de cargas de malta… lo cual no suena muy lógico. Podrías omitir el rendimiento del macerador con el que elaboras esas recetas si confeccionas la receta por medio de porcentajes, así la cantidad puede ser adaptada fácilmente dependiendo del macerador de cada cual.
Si sólo te dan pesos específicos, si quieres adaptar la receta a tu equipo, primero tendrías que calcular los porcentajes de carga de cada malta, y con esa información, la densidad objetivo, tu volumen de mosto en fermentador y tu rendimiento de macerado, puedes personalizarla en un periquete y sin ninguna dificultad gracias al concepto de Puntos de Densidad.
Vuelvo a remarcar el hecho de que quiero profundizar en el tema del rendimiento del macerado más adelante, porque hay mucho de qué hablar.
Y por último, no he hablado aquí de como estimar el volumen final del mosto con respecto al agua usada en el macerado, ya que también es material que da para otro post completo.




