El parti-gyle es una de las tradiciones cerveceras más antiguas que se conocen, y sin embargo, todavía muchos jombrigüeres o no lo conocen, o no lo usan, o lo hacen sin saber que se llamaba así. Creo que merece la pena conocer los detalles técnicos e históricos de lo que encierra esta expresión, y le vamos a dedicar este post.
Yendo al grano, resumiendo un poco el asunto, y como punto de partida, podemos decir que el parti-gyle es una técnica de elaboración que consiste en instrumentar un único macerado de malta con una única carga de grano en el macerador, de tal manera que gracias a una oportuna gestión del mismo y manejando por separado los diferentes mostos extraídos, podamos elaborar diferentes cervezas de una vez.
Esto implica poner agua caliente en la malta, vaciar el macerador, darle un uso a ese mosto hirviéndolo por separado, y volver a poner agua caliente en el macerador para seguir aprovechando los azúcares que han quedado en la malta, dándole otro uso diferente a este segundo mosto, y repitiendo la operación tantas veces como sea conveniente. Usualmente, esto se hace aprovechando el primer mosto (más denso) para hacer una cerveza potente y el resto de mostos (o la suma de ellos), para otra (u otras) cervezas.
Gyle
En nuestra afición, como en todas las demás, hay muchas palabras propias que fuera del círculo de cerveceros, son difíciles de entender; lo que se denomina “jerga”, sin dar más rodeos. La mayoría nos han llegado al español desde otras culturas y algunas son incómodas de traducir, y no se traducen. Otras, directamente, tienen una traducción muy difícil o imposible, por lo que se opta también por el hecho de no traducirse. Así, tenemos muchas palabras raras en nuestros textos de referencia, cuando esos textos son en castellano.
“Gyle” (\ˈgī(ə)l\) viene a significar, ni más ni menos, que “la cerveza que está en proceso de fermentación”, o más técnicamente “el mosto, una vez se ha puesto la levadura en él, y que está en proceso de fermentación para convertirse en cerveza”, es difícil de encontrar en diccionarios de inglés comunes, pero se puede acudir al Merriam-Webster [¡plink!]. La palabra está relacionada con la francesa “guiller”, del mismo significado, y en algunos casos, la grafía de la palabra era “gael” o “guile”.
“Parti” es más fácil de asimilar, puesto que viene del latín partīre, en su acepción de “dividir”.
Se usó mucho entre en los siglos XIV y XIX, y ahora ya es más complicada de encontrar, puesto que se perdieron muchas costumbres y palabras cuando la cerveza dejó de ser algo exclusivo de elaboraciones tradicionales y de monasterios y dio el salto a la industrialización de sus procesos. Así que de no ser porque define una técnica de elaboración muy antigua, probablemente la palabra en sí ya habría desaparecido del todo.
Nota curiosa: en los textos que leí para documentarme sobre el parti-gyle, me encontré con un verbo también en desuso, “to barm”, que venía a significar “añadirle levadura a algo” (como sustantivo, era equivalente a kraeusen)… Me pregunto si alguien se atrevería a usar el verbo “barmear” en español…
Parti-Gyle, históricamente hablando
Actualmente, lo usual es diseñar una cerveza partiendo de una receta en la que has previsto qué densidad vas a conseguir, extraer todos los azúcares posibles de dicha malta mediante un macerado simple, lavar la malta para arrastrar los azúcares residuales y potenciar tu rendimiento, y mezclar el mosto junto con el líquido del lavado para completar así la cantidad de mosto a hervir, y cumplir con tu objetivo de densidad. Suena lógico y fácil, sobre todo ahora que se dispone de un densímetro y de muchos conocimientos acerca de qué reacciones químicas suceden dentro del mosto.
Sin embargo, el proceso estándar de elaboración de cervezas hace siglos, no era éste, si no que por sistema, se ponía agua caliente en la malta molida, se sacaba el mosto tras el macerado y se le daba un uso concreto a dicho mosto. Luego, se volvía a poner agua caliente en la malta ya macerada para volverla a macerar (a menudo, añadiendo algo más de malta molina) y se volvía a sacar el mosto. Éste segundo mosto tendría una densidad menor, y se destinaría a elaborar una cerveza distinta. Se hacían más macerados, o se combinaban el primero y el segundo mosto, y se aprovechaba el tercero (o el resto) para hacer la famosa “small beer” (cerveza floja). Las posibilidades eran múltiples y dependía del sitio de elaboración y del maestro cervecero en cuestión. Es muy popular la historia de que en las casas donde se hacían cerveza, se aprovechaban los primeros mostos para elaborar las bebidas de los señores, y los criados se contentaban con los últimos.
Los primeros libros que ilustran las metodologías empleadas en la elaboración de cerveza de manera más o menos seria datan del siglo XVIII, y en ellos se encuentran muchos ejemplos del método comentado. Gracias al historiador Ron Pattinson (que tiene un blog interesantísimo [¡plink!]), que se ha encargado de investigar muchos de ellos, sabemos que esto era así. Y se percata del hecho de que lo realmente raro era elaborar una cerveza en la que se usaran todos los mostos mezclados para un único fin, y va más allá, la cerveza Porter (quien quiera conocer más detalles de la historia de la Porter puede leer este ameno post [¡plink!]), en un principio se denominaba “Entire”, ya que sí que se elaboraba “a partir de un macerado entero” (es decir, todos los mostos de un único macerado se recogían en la misma olla de hervido para crear un único lote con una densidad consistente), puesto que, gracias a la llegada del densímetro a finales de ese siglo, se empezaron a dar cuenta de cómo aumentar rendimientos y a manejar las densidades de una manera óptima.
Aun así, el parti-gyle no fue una tendencia en desuso, sino que se empezó a usar de una manera más sofisticada, al tener más control sobre los procesos. Las nuevas tecnologías como el densímetro (que ya lo habíamos dicho) y nuevas técnicas de malteado y macerado, hicieron que las fábricas cambiaran sus planteamientos de elaboración de cara al ahorro de costes y la búsqueda de la rentabilidad.
En las publicaciones del siglo XIX, lo normal es que hasta los cerveceros más pequeños tuvieran una cierta cantidad de cervezas en sus listas de precios… cualquier fábrica era capaz de venderte Stock Ales, diferentes Pale Ales, diferentes Milds, Table Ales y Stouts de diferentes potenciales, y esto se conseguía por medio de la elaboración parti-gyle, usualmente manejando entre tres y cuatro mostos de un mismo macerado, y sus diferentes combinaciones, no solo de mostos completos, sino de parte de ellos.
En el siglo XX, fueron los cerveceros escoceses los que más de aplicaron con esta técnica. Su costumbre era usar una misma receta básica y a partir de ahí, sacar diferentes mostos con diferentes potenciales de alcohol… las famosas 60/-, 70/-, 80/- y la Strong Ale. Para más detalles sobre la historia (fantasma) de las cervezas escocesas, se puede leer este otro post [¡plink!] también muy ameno…
Pero el parti-gyle no se detenía en el macerado… los cerveceros, que ya controlaban las densidades del mosto a placer, podían coger una parte de la producción ya embarrilada y cebarla con azúcar para potenciar su nivel alcohólico. Y como podían, pues lo hacían para sacar versiones más potentes, controlando también el nivel de producción de acuerdo a la demanda de dichas cervezas.
El uso de esta técnica empezó a decaer en la década de 1960, pero no se ha extinguido, sobre todo en Inglaterra, donde sigue siendo una forma habitual (y práctica) para hacer diferentes cervezas a partir de una única carga de malta. Fuller’s, por ejemplo, sigue haciendo sus cervezas Chiswick, London Pride, Export London Pride, ESB, ESB Export, Golden Pride y Vintage Ale mediante esta técnica. O la fábrica Woodforde’s en Norwich elabora una Barleywine de 7% y una Golden Ale de 4,3% partiendo de una misma receta. También sigue siendo lo normal en algunas fábricas alemanas para elaborar Bocks con distinto potencial e incluso en Bélgica, variaciones de algunas cervezas trapenses.
De hecho, hay quien apunta que este es el origen de que las cervezas belgas trapenses se llamen Triples, Dobles y Singles, siendo la Triple elaborada con el primer mosto, la Doble con el segundo y la Single con el tercero. O en Inglaterra, las famosas X que aparecían en las etiquetas de las cervezas, siendo las XXX las del primer mosto, las XX las del segundo mosto y la X, la del tercero.
El planteamiento correcto
Para una fábrica comercial, es bastante ventajoso, ya que puede que ciertas cervezas tengan un mercado limitado con menos demanda, por lo que hacer un lote entero de una Imperial Stout o una Barley Wine usando el 100% de la capacidad del mosto de su macerador sea algo poco rentable. O que su equipo esté limitado para conseguir una densidad muy alta (y hervir mucho tiempo también sea poco rentable)… Pero si el cervecero se plantea usar el parti-gyle y usar el primer mosto para hacer un lote pequeño con una densidad muy alta, puede hacer una operación rentable, usando el resto de material para un lote de una cerveza habitual con mayor cuota de mercado.
Esto es extrapolable a los jombrigüeres… sobre todo porque a algunos, elaborar 20, 30 o 50 litros de una cerveza con 10% de alcohol nos hacía mucha gracia al principio, pero cada vez la tendencia es moverse a cervezas de fácil consumo (o Easy Drinking, como nos cuenta nuestro amigo Antoineitor en este artículo [¡plink!]), así que te puedes pegar el gustazo de experimentar y hacer, el mismo día, unos pocos litros de una cerveza más exclusiva y usar el resto de mostos para conseguir otra receta más normalita. Además, te da el juego para usar dos cepas de levadura, lupulizar deferente (o no, y ver cómo afecta la densidad a un mismo planteamiento). Y siendo sincero, si elaboras 50 litros, a menos que en tu casa viva un equipo de futbol o tus amigos tengan más vicio que una garrota, elaborar un lote de esa cantidad de la misma variedad no siempre va a ser la mejor idea.
La flexibilidad de esta idea es infinita. Digamos que quieres hacer una Doble IPA con bastante alcohol, y sacas un primer mosto de tu macerador bastante subido de densidad. Nada te impide entonces añadir malta Chocolate o Cebada Tostada al macerador y usar los azúcares restantes en la malta para hacer una Dry Stout o una Brown Ale. Y si no añades las maltas tostadas, es posible elaborar una Ordinary Bitter, o añadirle azúcar al hervido del segundo mosto y convertir la cerveza en Pale Ale o IPA… el límite está en tu imaginación.
Pero no todo iba a ser fácil: vas a necesitar más equipo. Más fermentadores, y obviamente, al menos dos ollas para hacer hervidos distintos y sus correspondientes fuentes de calor. La clave para empezar en el parti-gyle pasa por invitar a otro compañero jombrigüer a tu casa, para que se traiga sus cacharros y elaborar de manera conjunta sin invertir en más equipo.
La experiencia de los jombrigüeres que han intentado esto no aconseja hacerlo con una sola olla, porque si tienes que esperar a hervir un mosto para luego hervir el otro, la jornada se hace interminable. Por otro lado, si lo que tienes pensado es guardar el mosto todo un día y una noche para hervirlo al día siguiente, la posibilidad de que en lugar de mosto tengas un líquido repugnante son muchísimas. Eso sí, si hierves a la vez, programa bien los tiempos para poder enfriar uno de los mostos cuando ya estés seguro de que el otro se encuentre a la temperatura correcta para “barmearlo”.
La teoría matemática
Vaya por delante que ni leyendo en foros, ni a los autores de los artículos de referencia, ni a amigos que lo han intentado, ni a mí mismo, les ha funcionado la teoría de densidades que todo el mundo maneja y que voy a explicar un poco más abajo. Sin embargo, a pesar de eso, se necesita un punto por dónde empezar, y como estimación, resulta una guía útil, así que a no ser que encuentres una teoría diferente, es la única por dónde empezar a hacer números hasta que hayas comprobado por ti mismo qué es lo que sale en la práctica con tu equipo.
Hazte a la idea de que la primera vez que hagas un parti-gyle, si atinas con las densidades, será por casualidad, y estate preparado para ajustar las densidades a la cantidad correcta si necesitas forzosamente entrar en un rango concreto, y prepárate para equilibrar los IBUs sobre la marcha. Conviene tratar las recetas como cervezas independientes a la hora de lupulizar y estimar el amargor.
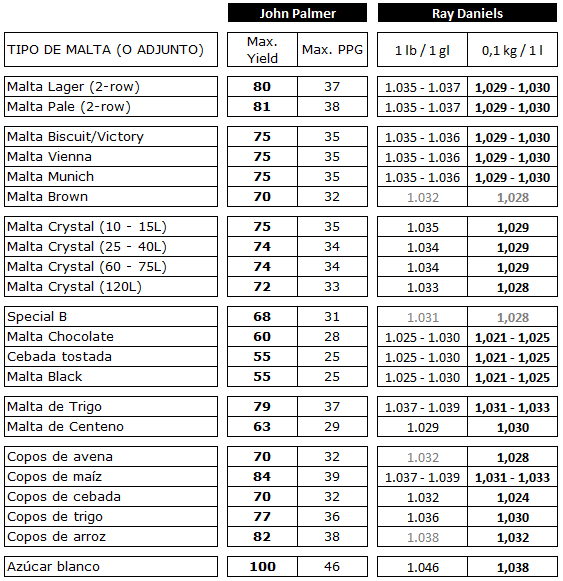
Quizás no estés familiarizado con el concepto de Puntos de Densidad y el texto a continuación te suene un poco a koreano, pero no hay problema, porque este tema quedó bien explicado en el último post [¡plink!].
Cuando nos planteamos hacer un lote parti-gyle, tenemos que pensar cómo vamos a dividir el mosto. Lo usual es dividir un mosto (el macerado + el lavado) en 1/3 + 2/3 o bien en 1/2 + 1/2.
Si dividimos el lote en 1/3 + 2/3, aproximadamente la mitad del extracto total va al primer tercio, mientras que la otra mitad del extracto iría a la parte más grande de 2/3.
Pongamos que queremos hacer 30 litros de cerveza con una densidad inicial de 1,060 para el lote completo, contando con que tenemos 1.800 Puntos de Densidad (30 litros x 60 del ‘factor denso’), así que vamos a estimar qué densidades conseguiremos dividiendo el mosto, usando la siguiente fórmula:
(1.800 Puntos de Densidad x 0,50) / 10 litros = 90
(1.800 Puntos de Densidad x 0,50) / 20 litros = 45
Concluyendo que los primeros 10 litros (1/3 de los 30 litros) podrán tener una densidad aproximada de 1,090, mientras que los 2/3 restantes (los otros 20 litros), tendrán una densidad de alrededor de 1,045.
Los lotes divididos en 1/2 + 1/2 tendrán alrededor del 58% del extracto total en el primer mosto, y un 42% en el segundo. Usando el mismo ejemplo que antes (lote de 30 litros con una densidad inicial programada de 1,060 para el lote completo), podremos estimar que los primeros 15 litros tendrán una densidad de unos 1,070 y la otra mitad del mosto, unos 1,050. La explicación se ve muy clara en el siguiente cálculo:
(1.800 Puntos de Densidad x 0,58) / 15 litros = 69,6
(1.800 Puntos de Densidad x 0,42) / 15 litros = 50,4
Como ya hemos dicho, no conviene fiarse al 100% de estos cálculos, puesto que estamos hablando de estimaciones (la realidad es que el equipo, la cantidad de malta usada y el ratio agua:malta entre otros factores suman una cantidad de variables infinitas imposibles de controlar).
Una buena idea para controlar los rendimientos de tu equipo es que cuando elabores la próxima vez sin hacer parti-gyle, midas las densidades separando los mostos (aunque luego los mezcles, como siempre, sólo haciendo una simulación) y te hagas una idea de cómo funciona. La experiencia dice que tendrás diferentes rendimientos si has planteado hacer una receta de densidad 1,050 o de 1,060 o de 1,070, así que es buena idea ‘tantear’ tu equipo para afinar más, más pronto.
Por supuesto, las elaboraciones Parti-Gyle permiten otras divisiones o planteamientos, por ejemplo, supongamos que vamos a coger el enfoque medieval de la elaboración de cervezas, donde conseguimos 3 mostos distintos, de igual volumen, macerando 3 veces la misma carga de malta. La estimación a seguir es la de que el lote del medio tendrá, más o menos, la misma densidad que la densidad programada para el lote completo. Para el primer mosto tendríamos que multiplicar dicha densidad por 1,5 y para el último, por 0,5.
Siguiendo con el ejemplo anterior, si hemos programado 30 litros a 1,060, los primeros 10 litros tendrán una densidad de 1,090 (60 x 1,5 = 90), los siguientes 10 litros la densidad programada, es decir, 1,060 y los últimos 10 tendrían 1,030 (60 x 0,5 = 30).
Y como digo, no tienes que quedarte ahí, puedes hacer muchas otras variaciones. Como por ejemplo, puedes mezclar partes del primer, segundo y tercer mosto para conseguir cualquier densidad que necesites. O puedes añadir extractos, azúcar o miel a los mostos más flojos para elevar su densidad y conseguir tres cervezas potentes (si eso es lo que realmente quieres). O puedes usar los dos primeros mostos para hacer una cerveza de densidad alta-media, y el último tercio del mosto para hacer una cerveza realmente ligera, o “aguachirri”… No se pueden cubrir todos los supuestos, pero creo que el texto es suficientemente descriptivo como para abrir la mente del jombrigüer y que, manejando los Puntos de Densidad, puedas estimar qué mostos vas a conseguir.
Conclusión
Llegados a este punto podemos concretar que el Parti-Gyle era el método inherente de elaboración de cervezas antes de 1780, pero que con la llegada del densímetro y un mayor control de los procesos de elaboración, dicha técnica empezó a ser una herramienta secundaria, pero a la vez, un método para ajustar las densidades y poder cumplir con la planificación de las elaboraciones de las fábricas.
A nivel jombrigüer, es ideal para hacer varias cervezas en un solo día e ir afinando las recetas a un ritmo más alegre, ya que la experimentación con volúmenes de cerveza más pequeños es menos problemático.
Referencias
Ron Pattinson (Revista Zymurgy, Noviembre/Diciembre 2014)
Terry Foster (Brew Your Own) [¡plink!]
Brad Smith (Brew Your Own) [¡plink!]
Randy Mosher (Morebeer) [¡plink!]