
A la hora de confeccionar una receta de cerveza, se requiere cierto conocimiento básico del funcionamiento de los ingredientes empleados y los procesos que se van a llevar a cabo. Hace algún tiempo, hablamos acerca de los Puntos de Densidad [¡plink!] que nos servían para saber cuánta cantidad de malta nos hacía falta en nuestras elaboraciones. El siguiente paso lógico, una vez tenemos claro eso, será saber qué cantidad de lúpulo tendremos que usar para que salga una receta equilibrada y lo más parecida a la que tenemos pensada. Dicho lo cual, el post de hoy hablará sobre las diferentes maneras de calcular los IBUS.
Como introducción, si no tenemos muy claro lo que es un IBU, podemos leer la entrada dedicada a explicarlo más o menos en detalle [¡plink!] aunque podemos condensarlo, saltándonos los detalles, y decir que es una unidad de medida de amargor. Si la distancia la podemos medir en kilómetros, la cantidad de amargor de una cerveza se mide en IBU. A priori, podríamos decir que una cerveza con 80 IBUs será más amarga que una que sólo tenga 20 IBUs, y digo “a priori” porque la sensación de amargor va a ir compensada por la densidad de la cerveza (que a la postre incidirá en el potencial alcohólico y en el dulzor residual), por lo que la sentencia sería correcta cuando hablamos de cervezas con la misma densidad inicial y final. Acerca de esto también habíamos hablado en este mismo blog: el índice BU:GU nos va a guiar a la hora de equilibrar nuestras cervezas y conseguir buenos resultados [¡plink!].
Como reflexión inicial, podemos decir que todo jombrigüer que se precie a sí mismo tendría que tener en cuenta ciertos cálculos antes de ponerse a elaborar. Por supuesto, las primeras cervezas que cada uno elabora, descubriendo el mundillo, son casi siempre elaboradas un tanto a ciegas siguiendo rituales, más que procedimientos. Y eso no es malo, si quisieras tener clara toda la teoría antes de lanzarte a elaborar tu primera cerveza, probablemente desestimarías esta afición antes de llegar a saber menos la mitad de lo aconsejable, por puro aburrimiento. Es más divertido lanzarse a la piscina e ir entendiendo los procesos viviendo en la piel los éxitos y los fracasos que todos los jombrigüeres con cientos de lotes a sus espaldas recuerdan con cariño.
No obstante, según vas controlando más y más procedimientos y variables, se hace más conveniente y necesario conocer los cálculos a los que nos referimos en la serie de posts a los que me gusta llamar “Matemática Cervecera”, aunque si lo tuyo no son las matemáticas ni perder el tiempo haciendo numeritos (que parece lo mismo, pero no es igual), por fortuna tienes cientos de miles de millones de softwares diferentes que harán estos cálculos por ti, como por ejemplo el famosísimo BeerSmith [¡plink!], el de Brew Your Own [¡plink!], el de Brewer’s Friend [¡plink!], la de la ACCE [¡plink!] o una de las más recientes, también de creación 100% española como la de la ACCE, y que podemos encontrar en la web de homebrewer.es [¡plink!].
En conversaciones con otros compañeros, cuando defiendo la conveniencia de conocer toda esta información, un argumento contrario es “en el siglo XVII no sabían lo que era un IBU y bebían cervezas tan tranquilos, no creo que sea para tanto…” Y no les falta razón en eso, sin embargo, me gusta replicar que “en el siglo VII ni siquiera había lúpulos en la cerveza y también las bebían tan tranquilos”. El hecho de que la inclusión del lúpulo sea un elemento relativamente reciente en la fabricación de cerveza todavía deja un poco descolocado al más pintado… Es evidente que la gente muere feliz sin conocer el concepto de IBU, pero las explicaciones que damos a continuación están dedicadas a quienes tengan inquietudes mayores, a quienes en lugar de elaborar cerveza por medio de “un ritual”, la quieran elaborar por medio de “un proceso lógico”. Quizás me ha quedado algo melodramático, pero no era la intención.
Asumimos, a partir de ahora, que tenemos claro cómo calcular la cantidad de malta, tenemos controlado qué es un IBU y la importancia del índice BU:GU a la hora de confeccionar nuestras propias recetas, así que empezaremos a definir los nuevos conceptos.
Factores importantes a tener en cuenta
Hay una serie de elementos que hay que tener muy presentes si queremos que nuestros lúpulos aporten a la cerveza lo que queremos, y serían:
El contenido de alfa-ácidos del lúpulo o lúpulos en cuestión. Suelen venir en una pegatina identificativa con los lúpulos que compras (si no la lleva, huye de esa tienda), y se expresan en un porcentaje. Se abrevia como %AA. En la foto podemos ver que el lúpulo Herkules (en pellets) tiene un 18% de contenido de alfa-ácidos.

La cantidad de lúpulo que vas a usar (y que trataremos de averiguar en este post). Es de Perogrullo, pero obviamente, a tu cerveza le va a afectar de manera diferente si le echas 10 gramos o 100 gramos de lúpulo. También habrá que tener en cuenta, como ya veremos, si el lúpulo está en flor o si está en pellets, puesto que influirá en los cálculos.
La tasa de aprovechamiento del lúpulo, o, dicho de otra manera, cuántos de esos alfa-ácidos que contiene van a ser “convertidos en amargor”, ya que en función del momento del hervido en el que adicionemos el lúpulo, tendrá un aprovechamiento distinto. Como en inglés esta tasa de aprovechamiento se conoce como “Utilization Rate”, mucha gente habla de ella diciendo “utilización del lúpulo”, lo que queda horrible, pero cada uno es muy libre de decirla como quiera (todavía hay gente en el mundo que dice que una cerveza está “balanceada” en lugar de decir “equilibrada”, que sería lo correcto, pero ese es otro debate). No trates de buscarla en la pegatina identificativa del lúpulo, puesto que no la vas a encontrar. Se trata de cálculos derivados de otros elementos, y que cada investigador ha desarrollado según su criterio. La veremos en detalle un poco más adelante. Utilizaremos la abreviatura “TA” en las fórmulas cuando hablemos de Tasa de Aprovechamiento, aunque en internet podrás encontrar muchas otras fórmulas que a este factor le llaman “U” o “U%”.
El volumen del lote es determinante a la hora de calcular los IBUs. Vuelve a ser obvio que no es lo mismo echar 20 gramos de lúpulo a una olla con 20 litros de mosto, que a otra con 50 litros. Algunas fórmulas tienen muy en cuenta la densidad del lote, otras no tanto y otras lo obvian. La teoría más reciente dice que en los mostos con más densidad, hay más dificultades para aprovechar los alfa-ácidos, por lo que se suele incluir un factor correctivo de acuerdo a este dato.
Los cuatro factores ya nombrados son los principales que vamos a manejar, aunque hay otros que complicarían los cálculos y que también son importantes, pero que por ahora ignoraremos. Un ejemplo sería el estado de conservación del lúpulo y/o su edad. Un lúpulo viejo o mal conservado habrá perdido %AA por puro deterioro y podría ser problemático. Otro ejemplo, la altura sobre el nivel del mar, ya que afecta a la temperatura de ebullición (cuanta más altura, menos temperatura requerida), y eso varía la tasa de aprovechamiento del lúpulo. Tampoco da lo mismo si echas el lúpulo a lo bruto en la olla, que si lo pones en una bolsita de tela o en una bola de acero inoxidable con agujeros, o si está en pellets o en flor (o sin haberse secado, es decir, recogidos directamente de la planta y puestos a hervir)…
Pero el factor más importante a tener en cuenta es que a pesar de todo lo indicado, y aun tratándose de matemáticas, no te obsesiones con decimales ni te lleves las manos a la cabeza por variaciones menores en los cálculos. Si tuvieras que elaborar un lote de 100.000 litros, te convendría ajustar mucho las cantidades para ahorrar costes. A la hora de elaborar el típico lote manejable de 25 litros (o incluso 50), podemos dejar que el rigor científico megalomaniaco se vaya a dar un paseo. Sobre todo, porque incluso la cantidad de %AA que viene en las bolsas y que vas a manejar con el mayor de tus cuidados, siempre es una aproximación.
Los distintos criterios (principales) a la hora de los cálculos
En este mundillo, siempre lo digo, es divertidísimo compartir pareceres porque además de que es perfectamente aplicable el “todo maestrillo tiene su librillo”, hay mil informaciones diferentes y algunas veces contradictorias que van creando corrientes de elaboración diferentes. Con el cálculo de IBUs para algo así. Ha habido diferentes investigadores acerca de este tema que han desarrollado su propio método (fórmula) para realizar el cálculo.
Hay opiniones para todo. Hay quienes se adhieren a un método por ser el más aproximado según la teoría, y hay quienes van a otros más sencillos y manejables obviando elementos importantes. Sea cual sea el método que elijas, también tendrás que ajustarlo a tu equipo y a tus gustos/impresiones en base a la experiencia. La única recomendación es que, sigas el método que sigas, trabaja sobre él y adáptalo a tu equipo con los ajustes que hagan falta.
Partimos de una base clara, que conviene explicar de manera más o menos sencilla. Los alfa-ácidos que están en el lúpulo van a ser los culpables de que a partir de ellos se formen los compuestos que van a aportar amargor a la cerveza. Dichos alfa-ácidos se dividen en tres compuestos específicos: la humulona, la cohumulona y la adhumulona.
Cuando soltamos alegremente el lúpulo en el mosto hirviendo, las altas temperaturas (la creencia más común dice que a partir de los 80 °C) provocan que estos alfa-ácidos sufran un cambio estructural. El cambio en sí mismo, se llama “isomerización” [¡plink!], y da pie a que surjan los compuestos amargos solubles que nos vamos a encontrar en la cerveza final. Cuando un alfa-ácido es isomerizado, tenemos que empezar a hablar de iso-alfa-ácidos. Los químicos, tras un simposio mundial y muchas horas de deliberación (y bastantes heridos en las discusiones que derivaron en violencia), decidieron llamar a estos compuestos iso-humulona, isu-cohumulona e iso-adhumulona.
No todo es tan sencillo, cabe apuntar que el lúpulo también contiene beta-ácidos (también llamados resinas blandas), que al isomerizarse también aportar amargor. Sin embargo, la solubilidad de estos ácidos es tan baja que no merece la pena tenerlos en cuenta a nivel jombrigüer. A menudo se dice que los beta-ácidos tienen entre un tercio y una décima parte de ‘potencial amargante’ que los alfa-ácidos. Sin embargo, cuando el lúpulo envejece, pierde alfa-ácidos y gana beta-ácidos (y por eso es atractivo jugar con lúpulos viejos en algunas ocasiones). Y hay otros elementos ajenos a los alfa-ácidos, como pueden ser productos oxidados durante la recolección y almacenamiento del lúpulo que también aportan amargor y que nadie los mide… ¡qué divertido!
En resumen, es importante saber que la formación de iso-alfa-ácidos durante nuestro hervido va a depender directamente los factores que ya hemos hablado en el párrafo anterior: cantidad de lúpulo que entra en la olla, tasa de aprovechamiento, contenido en alfa-ácidos del lúpulo usado y volumen del lote.
La Tasa de Aprovechamiento (TA), el Factor de Aprovechamiento o “Utilización” (U%)
La manera más rápida de definir la tasa de aprovechamiento del lúpulo (o el “factor de utilización”, como se suele encontrar en la web) es el porcentaje del total de alfa-ácidos que finalmente se convertirán en iso-alfa-ácidos. Es decir, que no el 100% de los %AA que tiene un lúpulo van a quedarse en la cerveza. Además de que se requiere cierto tiempo para que el proceso de isomerización se lleve a cabo, no todos sufren la conversión, y otros que sí la sufren, se pierden en el propio proceso de elaboración.
Dicho esto, podemos deducir que la tasa de aprovechamiento del lúpulo será mayor cuanto más tiempo esté en contacto con el mosto hirviendo. Por eso, dependiendo del momento en que adicionemos los lúpulos tendremos una tasa de aprovechamiento distinta. Y por eso se dice que los lúpulos de amargor se añaden al principio del hervido, y los lúpulos de sabor y aroma en la recta final.
Las “líneas rojas” donde una adición pasa a ser de “amargor” o de “sabor”, o de “sabor” y “aroma” no están claramente definidas, pero se estima que entre el inicio del hervido (minuto 90 o 60, dependiendo, y el minuto 30-25) es una adición puramente de amargor. La explicación a esto es que todos los compuestos aromáticos del lúpulo se destruirán (o se escaparán durante la evaporación) con el tiempo de hervido. Para que el sabor del lúpulo se quede en el mosto, por las cuestiones de que ya no le da tanto tiempo a los alfa-ácidos a isomerizarse y porque los aceites esenciales del lúpulo ya no se van a disipar tanto en el hervor, se habla de un rango que va desde el minuto 30 (siendo el minuto 0 cuando apagamos el fuego) hasta el minuto 10-7, mientras que, si queremos conservar algo de aroma, estimamos entre 10 y 7 minutos de hervor, hasta el minuto 0, que es cuando apagamos el fuego (o resistencia eléctrica) y detenemos el hervido. En definitiva, cuanto más cerca del final del hervido, más aromas y sabores del lúpulo quedarán en el mosto. El gráfico cutre que he puesto (con las cifras de minutos más conservadoras), ilustra este párrafo.
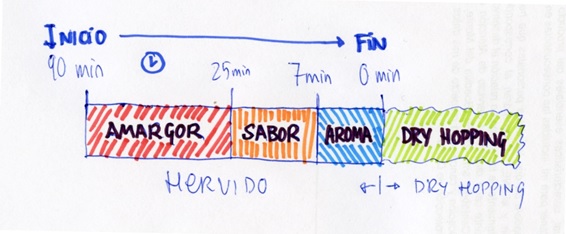
A partir de que apagamos el fuego (minuto 0), y hasta que la cerveza baja de 80 °C, todavía tenemos temperaturas propias de isomerización, por lo que, si tardamos mucho en bajar ese rango al enfriar, podemos conseguir IBUs extra con los que no contábamos en nuestros cálculos. Esto debe ser tenido muy en cuenta si usamos un método de enfriado lento, hacemos “whirpool”, o directamente no enfriamos usando el conocido método “no-chill”, en el que simplemente se tapa el mosto para evitar contaminaciones y se le deja que enfríe pasando el tiempo, incluso hasta 24 horas.
Como todo en esta afición, lo que acabamos de comentar no es tan simple. Hay otros factores que no podemos evaluar y que influyen en el aprovechamiento de los %AA. Por ejemplo, el vigor del hervido afecta al aprovechamiento del lúpulo. Cuanto más vigoroso, habrá más isomerización de alfa-acidos, pero es algo que no puedes medir de otra manera que no sea “a ojo”. Lo suyo es procurar siempre hervidos iguales en potencia para poder acomodar tus recetas a tu equipo. Así, además, podrás prever y controlar la evaporación además del aprovechamiento.
Incluso la levadura que pongas a la hora de fermentar influirá en el aprovechamiento de los %AA. Se ha comprobado que, a mayor cantidad de levadura inoculada en el mosto, menores rangos de IBUs finales se consiguen a causa de una mayor precipitación de iso-alfa-ácidos junto con la levadura. Pero no solo la cantidad de levadura influirá, sino que también la densidad inicial de fermentación, la cantidad de oxígeno, nutrientes y temperaturas de fermentación influirán en los IBUs finales. Sin olvidarnos de agentes clarificantes que además de precipitar las proteínas que provocan turbidez en la cerveza, también arrastrará iso-alfa-ácidos al fondo del fermentador. Incluso la geometría de la olla (es decir, la forma y la capacidad de la misma) o del fermentador también influirán, el pH y la composición del agua harán de las suyas a la hora de percibir el amargor en la cerveza. Así que, por favor, deja la megalomanía en la puerta antes de entrar.
Glenn Tinseth desarrolló un gráfico en el que vemos cómo la curva de aprovechamiento no es lineal y que cae de manera espectacular en la recta final del hervido, lo que reafirma lo que ya sabíamos.
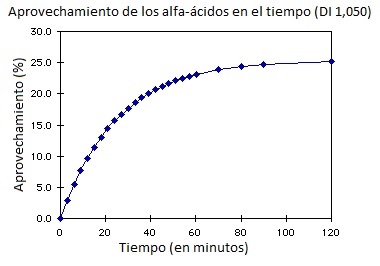
Lo realmente importante es saber y tener claro que la tasa de aprovechamiento no va por escalones, si no que se trata de una curva descendente en función de lo cerca que esté el final del hervido, el gráfico lo deja muy claro.
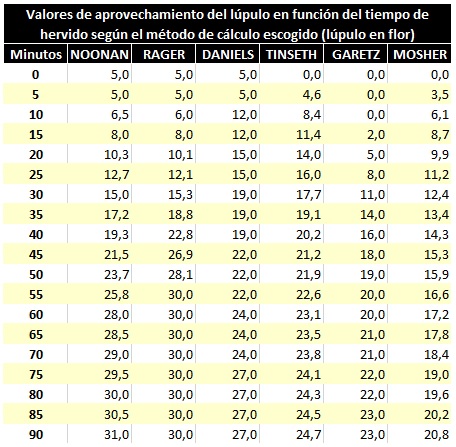
Sin embargo, podemos decir que precisamente este el “punto conflictivo” entre los diferentes investigadores del tema. Cada uno, basándose en su experiencia, ha declarado unas Tasas de Aprovechamiento diferentes. Algunos son más conservadores, otros más optimistas, otros tienen resultados similares en algún punto del tiempo de hervido, pero se desvían en otros… Por tanto, dependerá de nosotros mismos y nuestra experiencia ajustar los valores que usemos en nuestros cálculos. Aquí podemos ver una tabla comparativa entre diferentes puntos de vista:
Fórmula IBU
Una de las primeras investigaciones para cálculo de IBUs, a nivel jombrigüer, se llevó a cabo en 1990 por Jackie Rager y fue publicada en la revista Zymurgy. Años más tarde, en 1997 Michael L. Hall escribió un artículo sobre este tema en la misma revista muy interesante y que está disponible para consultar libremente en la web de la AHA [¡plink!], donde además compara otras metodologías y profundiza en detalles técnicos (y que ha servido de inspiración para este post).
La mayoría de investigadores se centran en una fórmula de cálculo (más o menos común) cuya principal diferencia la tenemos en el cálculo de la Tasa de Aprovechamiento. Escritores cerveceros como Ray Daniels en Designing Great Beers, Randy Mosher en Radical Brewing o Mark Garetz en Using Hops (que curiosamente tiene los números más conservadores, y que no tiene en cuenta ningún aprovechamiento del lúpulo para los tiempos cortos de hervido) han desarrollado este tema en detalle. Por supuesto, Jack Rager (que fue el primero) debe ser un referente, aunque tiene los valores de aprovechamiento más altos que el resto de investigadores, y Glenn Tinseth y Greg Noonan también tienen su cuota de aportación en este tema.
La ecuación básica para la estimación de IBUs es la siguiente:
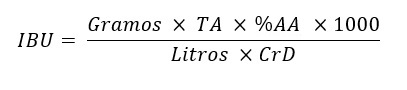
En fórmula lineal podemos expresarlo como:
IBU = (Gramos x TA x %AA x 1000) / (Litros x CrD)
Donde:
Gramos es el peso del lúpulo añadido en gramos.
TA (U% en la fórmula original) es el factor de aprovechamiento del lúpulo (del inglés “Utilization”), y se expresa como decimal. Es decir, que un factor de aprovechamiento del 9%, se expresará en la fórmula como 0,09. Este dato se consulta en una tabla específica, pero hay varios criterios para su cálculo, y hablaremos de ello más adelante.
%AA es el contenido de alfa-ácidos del lúpulo, que te lo da el distribuidor y viene siempre en las etiquetas del lúpulo. Se expresa también como decimal (por ejemplo, 16% de alfa-ácido, sería 0,16)
Los litros se refieren al volumen del mosto final, o lo que es lo mismo, lo que irá al fermentador. Se supone que tendrías que conocer tu equipo al dedillo para saber estimar cuánto mosto te quedará en función del volumen hervido y la tasa de evaporación, teniendo en cuenta el vigor de dicho hervido. Pequeñas variaciones en este dato provocarán desvíos en el resultado, así que conviene estudiar las fórmulas antes y después de elaborar, para ir ajustándolas.
CrD quiere decir “Corrector de Densidad”, ya que la isomerización disminuye cuando el mosto es más denso. Hay diferentes interpretaciones a este cálculo, y algunos investigadores ni lo tuvieron en cuenta en su momento. No obstante, merece la pena verlo en detalle.
Corrector de Densidad
Algunas visiones para calcular este corrector son bastantes simples (como, por ejemplo, la de Ray Daniels). Cuando el mosto, antes del hervido, tiene una densidad de 1,050 o menos, dicho factor corrector es 1 (y nunca puede ser menos de 1). Si el mosto tiene más de 1,050 antes del hervido el factor corrector será mayor que 1, de acuerdo a la siguiente fórmula:
CrD = 1 + [(Densidad Hervido – 1,050) / 0,2]
Como ejemplo, si nuestro mosto antes de hervir tuviera una densidad de 1,080, el CrD sería:
CrD = 1 + [(1,080 – 1,050) / 0,2]
CrD = 1 + (0,03 / 0,2)
CrD = 1 + 0,15
CrD = 1,15
Hay otra fórmula más ambiciosa para calcularlo, sobre todo a la hora de estimar la densidad del hervido, que tiene en cuenta el volumen del mosto y su variación por evaporación, y que sería tal que así:
Densidad Hervido = [(DAH – 1) x VF / VI] + 1
Donde:
DAH: Densidad Antes de Hervir
VF: Volumen de litros finales (después de hervir)
VI: Volumen de litros antes de hervir
Por tanto, imaginad que, en el ejemplo anterior, teníamos la DI antes de hervir de 1,080, y que queremos hervir un volumen de 28 litros para quedarnos en 24 (por la evaporación). Por tanto:
Densidad Hervido = [(1,080 – 1] x 24 / 28] + 1
Densidad Hervido = [(0,08 x 24) / 28] + 1
Densidad Hervido = (1,92 / 28) + 1
Densidad Hervido = 0,069 + 1
Densidad Hervido = 1,069
Por tanto, si aplicamos la fórmula anterior, en realidad el factor corrector sería:
CrD = 1 + [(1,069 – 1,050) / 0,2]
CrD = 1 + (0,019 / 0,2)
CrD = 1 + 0,095
CrD = 1,095
Entre un cálculo y otro hay una diferencia de 0,055 que variará en algo (poco) el resultado del cálculo.
Ejemplo de cálculo de IBU aportado en una adición de lúpulo
Vayamos, por fin, a la práctica (o mejor dicho, a la práctica de la teoría). El uso de la afamada fórmula nos puede responder a la sencilla pregunta de “¿cuántos IBUs estoy aportando a mi cerveza?”. Veamos un ejemplo.
Bruno, avezado jombrigüer de Pales Ales sin igual, está elaborando una de sus recetas, donde tiene un mosto de 1,040 antes de hervir, y una única adición de 30 gramos de lúpulo Hungendog con 9% de alfa-ácidos en el minuto 90, para su lote habitual de 24 litros finales. De repente, levanta la vista, se rasca la barbilla y con voz temblorosa replica “¿y cuántos IBUs estoy aportando a mi cerveza, oh, Dios misericordioso?”. Por lo que si Bruno realmente quisiera saberlo tendría que aplicar la mencionada fórmula.
Por tanto, estos serían los resultados según el perfil de Aprovechamiento escogido (hay que consultar la tabla-resumen y buscar el valor de TA correspondiente (ojo, los valores de la tabla son %, por lo que se tienen que expresar en formal decimal, esto es que un valor de 25 se debe expresar en la fórmula como 0,25)
IBU= (30 x ¿TA? x 0,09 x 1000) / (24 x 1) = ¿?
Noonan: IBU= (30 x 0,31 x 0,09 x 1000) / (24 x 1) = 34,88 IBUs = 35 IBUs
Rager: IBU= (30 x 0,30 x 0,09 x 1000) / (24 x 1) = 33,75 IBUs = 34 IBUs
Daniels: IBU= (30 x 0,27 x 0,09 x 1000) / (24 x 1) = 30,38 IBUs = 30 IBUs
Tinseth: IBU= (30 x 0,247 x 0,09 x 1000) / (24 x 1) = 27,79 IBUs = 28 IBUs
Garetz: IBU= (30 x 0,23 x 0,09 x 1000) / (24 x 1) = 25,88 IBUs = 26 IBUs
Mosher: IBU= (30 x 0,208 x 0,09 x 1000) / (24 x 1) = 23,40 IBUs = 23 IBUs
Como se ve claramente, hay una diferencia bastante grande entre la estimación de Mosher, la más conservadora con 23,40 IBUs y la de Noonan, más optimista, de 34,88 IBUs. Hablamos de 11,48 IBUs entre uno y otro. Ya dijimos en otro post cuando hablamos de los IBUs que el ser humano no puede distinguir entre (por ejemplo) 35 y 36 IBUs, sino que se cree que nota las escalas de IBU de 5 en 5. Es decir, que sí notaría la diferencia entre 31 y 36 IBUs.
Por tanto, hay que poner en práctica estos cálculos y saber cómo afectan a tu cerveza para ir ajustando tus formulaciones según tus experiencias.
Cálculo de la cantidad necesaria de lúpulo
A pesar de todo lo dicho, el cálculo realmente útil se hace a la hora de diseñar la receta de la cerveza. Es decir, días antes de la elaboración, cuando te planteas el estilo de cerveza a elaborar y los lúpulos que vas a utilizar (o los que tienes disponibles).
De forma natural y por regla general, primero decides el estilo de cerveza a elaborar. Para hacerlo de manera práctica, veamos un ejemplo, y pongamos que queremos hacer una Ordinary Bitter. Sabemos que tenemos que estimar una D.I. de 1,030 – 1,039 según la BJCP (a la que podremos hacer caso o no, ese no es el debate que hoy nos ocupa), y nosotros apuntaremos a 1,039 (si llegados a este punto todavía no sabes cómo calcular la cantidad de malta para alcanzar esta densidad, ve a siguiente post [¡plink!]). El rango de IBUs para este estilo es de 25 a 35. Deseamos una cerveza que el lúpulo tenga presencia, pero sin ser el protagonista total, por lo que apoyándonos en lo que sabemos del índice BU:GU [¡plink!] decidimos que 25 IBUs estará muy bien para esa densidad, ya que en el gráfico está en el límite de “cerveza poco lupulizada” y “muy lupulizada”, y cuyo índice BU:GU (25/39 = 0,64) nos da un equilibrio apreciable. Como sólo disponemos en el congelador 4 kilos de lúpulo Hungendog (procedentes de la última compra conjunta) con un contenido de alfa-ácidos del 8%, la pregunta es sencilla. Si mi lote habitual es de 22 litros finales, ¿cuántos gramos de lúpulo Hungendog con 8 %AA tengo que poner en el minuto 90 de hervido para alcanzar mis 25 IBUs deseados?
Para averiguarlo, no hay más que darle la vuelta a la fórmula establecida, usando lo que hemos aprendido en la EGB para la resolución de ecuaciones (o directamente, usando la que te pongo aquí mismo):
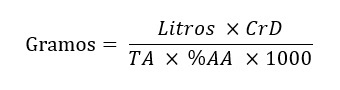
De forma lineal podemos expresarla como:
Gramos = (Litros x CrD x IBU) / (TA x %AA x 1000)
Y en nuestro ejemplo, sería:
Gramos = (22 x 1 x 25) / (¿TA? x 0,08 x 1000) = ¿?
Por lo tanto, según el perfil de Aprovechamiento que escojamos, tendríamos que añadir estos gramos:
Noonan: Gramos = (22 x 1 x 25) / (0,31 x 0,08 x 1000) = 22,18 g. = 22 gramos
Rager: Gramos = (22 x 1 x 25) / (0,30 x 0,08 x 1000) = 22,92 g. = 23 gramos
Daniels: Gramos = (22 x 1 x 25) / (0,27 x 0,08 x 1000) = 25,46 g. = 25 gramos
Tinseth: Gramos = (22 x 1 x 25) / (0,247 x 0,08 x 1000) = 27,83 g. = 28 gramos
Garetz: Gramos = (22 x 1 x 25) / (0,23 x 0,08 x 1000) = 29,89 g. = 30 gramos
Mosher: Gramos = (22 x 1 x 25) / (0,208 x 0,08 x 1000) = 33,05 g = 33 gramos
Obviamente, en la práctica redondearíamos gramo arriba, gramo abajo. No obstante, hay una diferencia de unos 11 gramos entre un planteamiento y otro. Por tanto, seguimos diciendo que conviene hacer cálculos y ver los resultados para saber por dónde nos movemos.
¿Complicando el asunto? Adiciones de sabor y aroma
Todo esto está fenomenal, pero habitualmente las cervezas que nos gustan elaborar tienen más de una adición de lúpulo. Y como ya hemos explicado al principio del post, suelen determinarse para aportar aroma y sabor.
Es bastante más simple de lo que parece. En serio. Realmente, hay que tener en cuenta que las aportaciones para aroma y para sabor son las que menos amargor aportan, habida cuenta de su poco aprovechamiento. Por tanto, la cantidad de gramos para estas adiciones se estiman en proporción al lote. Por ejemplo, una regla sencilla por dónde empezar tu carrera de diseño de recetas es empezar por 1 gramo/litro final de cerveza. Es decir, por ejemplo, si tu lote es de 24 litros, poner 24 gramos de lúpulo a los últimos 5 minutos (para aroma) y 24 gramos de lúpulo a los últimos 15 minutos (para sabor). Cuando sepas cómo afecta esto a tu cerveza, podrás ir ajustando hacia arriba o hacia abajo, o jugar con los tiempos de adición. Ojo también porque hay lúpulos más aromáticos que otros y habrá que ajustar las cuotas.
Una vez hayas establecido la cantidad de lúpulo añadido en sabor y aroma, tan sólo tienes que calcular cuántos IBUs aporta cada una de esas adiciones con la fórmula que hemos visto. Luego, restar esos IBUs de la cantidad de IBUs totales a aportar a la cerveza, y mediante la otra fórmula que ya conocemos para calcular la cantidad necesaria de lúpulo, hacer el ajuste de amargor.
Por si no ha quedado claro, veamos un ejemplo práctico más:
Para no complicarnos con los diferentes planteamientos, escogeremos el de Ray Daniels (que personalmente es el que yo uso, con buenos resultados) para este ejemplo. Pongamos que queremos hacer la receta-clon de una Rogue Chocolate Stout Clone que podemos encontrar aquí [¡plink!] y que nos da la siguiente información:
28 g de Cascade (pellet) con 5 %AA a los 90 min.
28 g de Cascade (pellet) con 5 %AA a los 30 min.
28 g de Cascade (pellet) con 5 %AA a los 0 min.
Además, nos dice apuntar a una densidad inicial de 1,069 y buscar los 30 IBU. Veamos entonces cómo podemos reinterpretar esta receta.
Para empezar, hemos comprado Cascade y solo hemos podido encontrar en flor, con un %AA de 6,4, por lo que no empezamos muy bien. Además, la receta estima esas cantidades de lúpulo para un lote de 19 litros, pero yo elaboro 25. Seguimos mal. ¡¡Pero no pasa nada, porque ya sabemos cómo actuar!!
Lo primero es calcular cuántos IBUs nos van a aportar las adiciones de aroma y sabor. Si en la receta que queremos adaptar usan 28 gramos para un lote de 19 litros, sabemos que están usando 28/19= 1,47 g/l, así que ya sabemos por dónde empezar. Como nuestro lote será de 25 litros, usaremos 1,47 x 25 = 37 gramos de lúpulo.
Se da la circunstancia de que tenemos una DI por encima de 1,050 por lo que hay que aplicar el corrector (CrD). Sabemos (porque conocemos nuestro equipo y nuestra evaporación) que al hervir 90 minutos se nos evaporan unos 7 litros, por lo que tenemos que empezar con 32 litros en la olla, a una densidad antes de hervir de 1,054 (si no sabes porqué, ver este post [¡plink!]), por lo que aplicando la fórmula:
CrD = 1 + [(Densidad Hervido – 1,050) / 0,2]
CrD = 1 + [(1,054 – 1,050) / 0,2]
CrD = 1 + (0,004 / 0,2)
CrD = 1 + 0,2
CrD = 1,2
IBUS que aporta la adición de 37 gramos de lúpulo Cascade flor con 6,4 %AA en el minuto 0 (según Daniels):
IBUs= (37 gramos x 0,05 x 0,064 x 1000) / (25 x 1,2) = 3,94 IBU (4 IBU)
Y seguimos con la segunda adición: IBUS que aporta la adición de 37 gramos de lúpulo Cascade flor con 6,4 %AA en el minuto 30 (según Daniels):
IBUs= (37 gramos x 0,19 x 0,064 x 1000) / (25 x 1,2) = 14,99 IBU (15 IBU)
Ya hemos averiguado que las dos adiciones finales nos aportan un total de 4 + 15 = 19 IBUs. Como la receta apunta a 30 IBU, tenemos que calcular cuántos gramos de nuestro lúpulo tenemos que poner en la olla en el minuto 90, pero para aportar 30 – 19 = 11 IBUs.
Así que, aplicando la otra fórmula, tenemos que:
Gramos = (25 x 1,2 x 11) / (0,27 x 0,064 x 1000) = 19 gramos
Ya tenemos algo por donde elaborar nuestro primer lote de este clon, evaluar los resultados e ir ajustando la receta hasta darle el toque definitivo, pero con resultados aceptables desde el principio.
Ray Daniels (quien me conoce o lee asiduamente este blog, ya sabe lo mucho que me gusta su libro “Designing Great Beers”) le dedica el capítulo 9 a esta temática, y emplea varias páginas a la adaptación de los cálculos de los factores de aprovechamiento a tu equipo y procesos, por lo que, si eres muy friki, puedes investigarlo para tener unos cálculos más ajustados (aunque no es el único, hay muchas publicaciones en internet sobre el tema). También juega con otros pormenores muy interesantes, como, por ejemplo, quienes hierven una cantidad determinada de cerveza, pero luego la diluyen con agua en el fermentador, cómo tener en cuenta este hecho para acertar con los IBUs, o el cálculo de degradación de los alfa-ácidos en los lúpulos de acuerdo a su edad, variedad, y temperatura de conservación.
Consideraciones finales
Algunos jombrigüeres son muy aficionados a poner el lúpulo tan pronto el mosto está saliendo del macerador. A esta técnica se la conoce como “First Wort Hopping” o FWH, y se cree que tiene efectos positivos en el aroma del lúpulo, así como que proporciona un amargor más redondo e integrado. Si quieres tener en cuenta el aporte de amargor de estos lúpulos, muchos softwares cerveceros lo estiman en un 10% superior al punto de empezar el hervido.
Otros cerveceros ponen el lúpulo directamente en el macerado, con la creencia de que esto potencia el aroma del lúpulo. Sin embargo, la tasa de aprovechamiento del amargor es mucho menor, y se suele estimar en un 20% del valor de aprovechamiento del tiempo de hervido equivalente (es decir, la duración del macerado).
Cabe destacar que, para lotes más grandes de 100 litros, las tasas de aprovechamiento del lúpulo se disparan, y muchas microcervecerías consiguen valores de aprovechamiento de un 300% con respecto a un jombrigüer y su lote casero de 20 litros. Conviene, como siempre, ajustar los valores a tu equipo concreto.
El deterioro del lúpulo tampoco es el mismo para todas las variedades, ya que algunas soportan mejor el almacenamiento que otras. Sin embargo, las estimaciones caseras para este factor son del 50% de alfa-ácidos si el lúpulo tiene un año y no ha sido conservado en frío, y 25% si sí ha estado conservado en frío. Como aproximación, puedes volver a hacer el mismo cálculo para el siguiente año (y posteriores), pero obviamente siempre serán estimaciones.
Los pellets se disuelven prácticamente por completo cuando se añaden al hervido, haciendo que los alfa-ácidos estén más disponibles y se isomericen más fácilmente. La diferencia entre la tasa de aprovechamiento de lúpulos en flor y en pellets suele cuantificarse en un 10% (es más potente el pellet que la flor), sin embargo, dependiendo de la fuente consultada, puede aumentar hasta un 15-25%. Tendrás que ajustar la tasa de aprovechamiento con el porcentaje que estimes ajustado a tu equipo (de entre un 10 a un 25%).
En los trasiegos, perderás IBUs, si quitas mucho turbio antes de la fermentación, perderás IBUs. Si filtras, perderás IBUs. Si usas agentes clarificantes, perderás IBUs.
Sobre usar lúpulo fresco (fresh hopping), o lo que es lo mismo, coger lúpulo de la planta y echarlo a la olla de cocción, hay bastantes visiones de cuánto echar y cómo afecta esto a los IBUs. En primer lugar, lo más recomendable es usarlos sólo para aroma, puesto que el lúpulo tiene la manía de crecer en la planta sin la etiqueta que te dice cuántos alfa-ácidos contiene. En el caso de que hagas una estimación de los %AA haciendo una media con los rangos habituales de la variedad en concreto (y aciertes), diferentes publicaciones de internet te dicen de echar entre 5 y 8 veces la cantidad necesaria. Una vez me contaron que el lúpulo seco tiene un 8% de agua, mientras que el resto (92%) es materia sólida. La flor fresca se estima que es un 80% agua y un 20% materia sólida. Si divides 92 / 20 te sale que necesitas 4,6 veces más de flores frescas que secas para una misma aportación de materia sólida. Con estas estimaciones, si tienes en cuenta (y sabes la manera de calcular o estimar el contenido de agua de tu flor), puedes variar la cuota a adicionar.
Hago todas estas consideraciones, exponiendo todos los factores incontrolables no para que el jombrigüer se corte las venas, sino porque considero necesario saber de antemano que estamos jugando con estimaciones y con teorías, y que incluso a pesar de todos esos factores que no podemos cuantificar, podemos obtener buenos resultados usando estos cálculos y teniendo consistencia en los procesos de elaboración. Y porque si repetimos lotes y tenemos resultados diferentes, podemos identificar qué proceso hemos hecho diferente y por donde viene la diferencia.
¡Eh! ¿Y el dry hopping?
El “dry hopping” o lupulización en frío, explicándolo de manera rápida, es la adición de lúpulo durante la fermentación (o después de ella) para aportar aceites aromáticos del lúpulo a la cerveza sin haber hervido dicho lúpulo. Según hemos visto en este artículo, la teoría nos dice que, al no haber hervido, no tendría lugar la isomerización de los alfa-ácidos y por tanto no habría aporte de amargor. Sin embargo, también hemos dejado caer que el lúpulo tiene otras sustancias amargantes que nadie suele tener en cuenta, porlo que una corriente de elaboradores sí insiste en que tiene cuota de amargor, aunque desdeñable desde otros puntos de vista. Esta técnica es muy útil, efectiva y divertida, y merece verla de cerca y en detalle, por lo que hablaremos de ella en otro post.
