El otro día, el blog de Hanselbier [¡plink!] hacía mención al libro «Vienna, Märzen, Oktoberfest», de George y Laurie Fix [¡plink!], como fuente de consulta enfocada a la elaboración de la cerveza elegida para el concurso de la ACCE que se celebrará en el evento “Madrid 2016”. La acertada decisión de Anselmo, de documentarse previamente a una elaboración, para ganar en coherencia y control de procesos, me entusiasmó tanto que he querido complementar su iniciativa con datos más concretos, con la sana intención de ayudar a quienes participen en dicho concurso.
Como siempre, conviene citar a los clásicos, y no hay “clásico” favorito en mi biblioteca que Ray Daniels y su “Designing Great Beers” [¡plink!]. El capítulo 26 de dicho libro (el penúltimo), se llama, concretamente, “Vienna, Märzen y Oktoberfest”, o de manera abreviada, VMO. Casi toda la información que vuelco en este post, proviene de dicho capítulo. Y casi toda la información que el bueno de Daniels investiga para escribir este capítulo, procede del libro de George y Laurie Fix. Así que vamos a leer un resumen del resumen.
Breve historia del origen del estilo
La fiesta del Oktoberfest es conocida en el mundo entero, ya no solo por quienes gustan de beber cerveza, sino también por cualquiera que tenga más sentido común que una ameba o un carpincho. Aunque no es momento para hablar de la historia del Oktoberfest propiamente dicho (ya lo haremos más adelante en Cerveza-Ficción), podemos decir que esta palabreja viene por evolución a designar las cervezas que se habían elaborado casi de manera exclusiva para esta celebración. De igual manera que Oktoberfest, también se las llama Märzen. De hecho, Märzen es la palabra primitiva para estas cervezas, y Oktoberfest, la popular. Dicho de otro modo, ya existían cervezas Märzen antes de que existiera el Oktoberfest como tal.
Para conocer el origen de estas cervezas, tenemos que pensar que antes de que existiera la refrigeración industrial, la elaboración de cerveza no era posible con el calor del verano, por lo que dicha actividad se suspendía en los meses más calurosos, retomándose con la llegada del otoño. Por supuesto, durante el verano se bebían las cervezas que se habían elaborado (y fermentado) durante los meses más frescos. Para conservarlas, además, se aprovechaban de las temperaturas cuevas naturales y bodegas frescas, pero sobre todo, aprendieron que si las hacían con una potencia de alcohol superior (una mayor densidad inicial), las cervezas se conservaban más y mejor. A las cervezas que elaboraban cada primavera, para almacenar y consumir durante el verano, se las empezó a llamar “cervezas de marzo” (es decir, “Märzenbier”). Varias fuentes relatan el hecho de que solían trabajar con bastante ahínco durante dicho mes para producir cuanta más cantidad de cerveza, mejor. Y se deja caer el hecho de que a la larga, el aroma/sabor del lúpulo decaía y se suavizaba mucho, lo que explicaría el perfil comercial de estas cervezas, hoy en día.
Sin embargo, y a pesar de que los muniqueses reclaman con ansias la autoría de este estilo de cerveza, no hay constancia de que fuera realmente así, sino más bien que nació de las elaboraciones habituales y tradicionales (sin un autor ni sitio fijo), y muy unido a las cervezas de Viena.
Tanto es así que, dentro de este grupo que podemos llamar VMO o “lagers ámbar” o “lagers ambarinas”, tenemos el subestilo “Vienna”, cerveza originaria de la ciudad homónima. Diferentes investigaciones datan las primeras referencias a la cerveza “Märzenbier” en Viena hacia 1732, mientras que en Munich y alrededores aparecen décadas después (como producto de la Hofbräuhaus München, en la segunda mitad del siglo XVIII). En otros sitios, se dice que la primera mención de cerveza “Merzen” se encuentra en libros de un libro de… ¡1581! [¡plink!]
Históricamente, y aunque Viena tenía más tradición vinícola que cervecera (su influencia como zona de avanzada romana pesaba en su bagaje), tuvo su primera fábrica de cerveza en el siglo XIII. A pesar de eso, el padre de la criatura vendría a ser una cerveza conocida como “braunes sommerbier” (o “sommer byer”), algo así como “cerveza marrón de verano”. Por aquellos tiempos, se solía diferenciar a la cerveza marrón en contraposición a la cerveza blanca, más clara, por tener más trigo que cebada.
Dicho esto, sabemos que en siglo XIX el estilo Märzen estaba muy definido en las fábricas vienesas, pero en algún momento (las malas lenguas, fanáticas de las leyendas y confabulaciones varias, atribuyen esta evolución a una amistad entre un cervecero vienés, Anton Dreher y un cervecero muniqués, Gabriel Sedlmayr), el estilo combinó las fermentaciones a bajas temperaturas (y sus levaduras) típicas de las lagers checas y alemanas con los métodos y recetas habituales, lo que dio lugar a la “lager de Viena” o “Vienna lager”. La versión Märzen, por aquel entonces, derivó a una cerveza más fuerte que la que se fabricaba para consumo diario. Y más tarde esa evolución saltó a Alemania (Munich) por imitación.
Por lo tanto, la cerveza marrón de verano (braunes sommerbier) que se elaboraba en origen en Viena, pasó a denominarse Märzen, y más adelante, Oktoberfest. Y de todos modos, si tuviéramos una máquina del tiempo y pudiéramos degustar una Märzen de Viena en el siglo XVIII o incluso XIX, poco o nada se parecerían a las de ahora. Y aunque esto es extensivo a todos (o casi todos) los estilos, conviene decirlo abiertamente.
Un año clave en la historia del estilo Vienna, fue 1841. Hasta entonces no tenían especial consideración, pero en aquel año (antes, incluso, que el “nacimiento” de la Pilsener en 1842), el ya nombrado Anton Dreher introdujo la elaboración de cerveza tipo lager en su fábrica, dando con la tecla que le haría famoso.
Si quisiéramos profundizar más en detalles históricos, parece que esta cerveza (dejando de lado malinterpretaciones, textos confusos y/o contradictorios y casuística típica de estas zarandajas), por lo visto existían tres variedades de este tipo de cervezas, la Abzug (lager de baja densidad enfocada al consumo rápido, tan rápido que se distribuía a los 8 días de su elaboración, y con un almacenaje máximo de 2 meses), la lager propiamente dicha (con una densidad más alta que la abzug, y que se almacenaba entre 4 y 10 meses) y la Marzën, más fuerte que la lager, y que se almacenaba hasta un año. Incluso se habla de una Doppelmärzen, con una densidad más alta que la Märzen.
Supongo que a los que siguen el blog, esto les puede sonar algo a los indicios y patrones normales del procedimiento de elaboración tradicional conocido como “Parti-Gyle” [¡plink!], ya que quitando el tema de las densidades, el resto de la formulación era similar. Nadie se atreve, sin embargo, a afirmar esto, ya que algunos dicen encontrar pruebas de que cada estilo se hacía con maltas sometidas a técnicas de secado/horneado diferentes. Esto parece ser evidente en algunas fábricas, pero no en todas. Pero de ser cierto, las cervezas resultantes tendrían, efectivamente, sabores diferentes provenientes de las maltas.
Como dato curioso, las tasas de lupulización de las lagers típicas de Viena eran un 30% más altas que las lagers de Bohemia, pero un 30% más bajas que las de Baviera. Lo que a alguien que probara las tres en un corto espacio de tiempo, le resultaría evidente (o no, porque tendríamos que tener en cuenta las distintas composiciones del agua y cómo afecta eso al amargor). El lúpulo usado en la mayoría de estas elaboraciones sería el Saaz (empleando los de mejor calidad para la Märzen, y el corriente, para las lagers más flojas). Hay constancias históricas de que el segundo de a bordo sería el Styrian Golding.
De todos modos, la documentación de la época compara constantemente las lagers de Bohemia con las de Viena, tanto en formulación como en procesos, destacando el macerado de decocción (va llegando el momento de dedicarle un post exclusivo a la decocción, así que estad atentos a la pantalla, porque ahora mismo no vamos a hablar de este proceso). Aun así, tanto las decocciones (número de escalones, temperaturas concretas y ratios agua:grano) como los hervidos (en tiempo) no eran iguales para cada zona geográfica, y de ahí venían, mayormente, sus diferencias.
La sorpresa que guarda este estilo llega en el siglo XX. Las guerras en Europa afectaron a su fabricación en origen, y la Prohibición en los Estados Unidos acabó de rematar a los emigrantes que se habían establecido allí y que elaboraban este tipo de cervezas. Por tanto, el estilo sobrevivió gracias a los cerveceros austriacos que se mudaron a México a finales del siglo XIX. Es curioso afirmar que los ejemplos más populares y acertados de las cervezas de estilo Vienna proceden de México; la Dos Equis y la Negra Modelo son ejemplos, pero no sé cómo serán allá en México, porque las que he probado en España en fechas recientes no han destacado por su espectacularidad (el abaratamiento de los ingredientes y los largos viajes hacen estragos).
Otro cantar es el sub-estilo Märzen, que ha incrementado su producción en la vieja Europa tanto en Alemania como en Austria, pero teniendo en cuenta que aquí, Alemania “ganó la guerra” y son los Austriacos los que imitan los usos muniqueses de formulación y procesos, arrastrados por el éxito de popularidad del Oktoberfest y la cerveza que se elabora (ya sin romanticismos) para dicha fiesta.
Hoy en día, es muy fácil encontrar cervezas comerciales bajo esta denominación, y aunque no tienen mucho que ver con las tradicionales (de hecho, raro es que se respeten incluso fechas de elaboración y procedimientos de maduración, ya que con los métodos actuales no es ni práctico ni rentable), se consumen de manera alegre y, por desgracia, se han ido “pilsenizando” de alguna manera. Esto es, una regresión al agua de grifo para evitar “no-gustar” a la mayoría de la gente y poder atacar a un mayor grupo de consumidores. Mención aparte a la cuota de mercado que el estilo Helles ha ganado con el tiempo, en detrimento de la Märzen.
A pesar de todo lo dicho, los salvadores de las causas cerveceras perdidas, también conocidos como los jombrigüeres, tenemos en nuestras manos el poder de recrear los brebajes que nos venga en gana. Así que con las siguientes líneas espero poder aportar mi granito de arena en todo esto.
Notas a la elaboración de cervezas Märzen
Como la finalidad del post es la de ayudar a la elaboración de este tipo de cervezas, de cara al concurso de la ACCE · Madrid 2016, vamos a dar una serie de consejos a los jombrigüeres que quieran participar en dicho concurso, o a quienes, simplemente, les apetezca elaborar este estilo.
Como preámbulo, cabe decir que la ACCE hizo una encuesta y que el estilo Oktoberfest/Märzen (3B) salió con un 43% de los votos, vapuleando a los otros estilos finalistas, la Russian Imperial Stout y la Belgian Trippel.
Estadísticas básicas
La BJCP, antes de su «revolución» de 2015, englobaba en la categoría 3, conocida como «European Amber Lager«, a la Vienna Lager (3A) y a la Märzen/Oktoberfest (3B), con los siguientes datos básicos:
3A (Vienna): D.I. 1,046 – 1,052; D.F. 1,010 – 1,014; IBU 18-30
3B (Märzen): D.I. 1,050 – 1,057; D.F. 1,012 – 1,016; IBU 20-28
Sin embargo, a partir de 2015 la Märzen (6A) se queda en la categoría denominada como «Amber Malty European Lager» y la Vienna Lager (7A) va a la «Amber Bitter European Beer«.
7A (Vienna): D.I. 1,048 – 1,055; D.F. 1,010 – 1,014; IBU 18-30
6A (Märzen): D.I. 1,054 – 1,060; D.F. 1,010 – 1,014; IBU 18-24
No vamos a entrar en el debate de si estos cambios eran necesarios y la motivación de los mismos, y mucho menos, en la adaptación de las densidades básicas y rango de IBU. Ya sabemos la arbitrariedad de estos valores y lo caprichoso de los estilos cerveceros (quien quiera saber mis disertaciones acerca de este tema, puede pasarse por este antiguo post [¡plink!]).
Y si nos quedamos sólo con la Märzen, si nos acogemos a las enseñanzas de Charles Papazian (The New Brewer, Marzo-Abril de 1992, páginas 25 a 28), sería así:
Densidad Inicial: 1,052 – 1,064
Densidad Final: 1,012 – 1,020
IBU: 22 – 28
Ratio BU:GU: 0,42 – 0,48
Como características adicionales, Charles Papazian apunta que el perfil de sabor debería ser maltoso, con aroma y sabor a lúpulo bajo, nada de ésteres y poco (o nada) diacetil. El ratio BU:GU ya apunta a un dulzor proveniente de la malta.
De todos modos, como último detalle, las notas de cata de la BJCP (en su versión de 2008 en español), en su apartado de Impresión general, dicen que la Vienna Lager se caracteriza por “su maltosidad suave y elegante, que otorga sequedad al final para evitar que se vuelva dulce”, mientras que la Märzen/Oktoberfest, que es la que nos interesa, es “suave, limpia, y bastante sabrosa, con un profundo carácter a malta. Es un ejemplo clásico de los estilos más maltosos, con una maltosidad que se suele describir como suave, compleja, pero nunca empalagosa”.
El agua de Viena
Como siempre que se habla de estilos tradicionales, hay que hablar del agua de elaboración, ya que en gran medida ha tenido la culpa del éxito de dicho estilo (porque si el agua es mala, el estilo en cuestión no hubiera pasado a la posteridad y no habría ocasión de hablar de él). Evidentemente, en este caso, se asume que el Danubio era la fuente principal. Pero otra vez las documentaciones se contradicen en las características del agua, y se deduce que aparte del río, había otros manantiales (en la época moderna, gran parte del agua potable de la ciudad venía de las montañas situadas a unos 60 kilómetros), por lo que en lugar de estudiar un perfil de agua de una estilo concreto, sería más acertado estudiar los perfiles de las aguas de cada fábrica que elaboraba dicho estilo.
La mayoría, podríamos decir, que derivaba en un perfil más bien duro. Ray Daniels recomienda usar un perfil de agua con menos de 100 partes por millón de carbonatos y unos 50 ppm tanto de calcio como de sulfatos. Y el resto de iones relevantes para la elaboración de cervezas, por debajo de 20 ppm. En su libro, explica que esa cantidad de carbonatos funcionaría muy bien con el perfil de sabor de las maltas tipo Vienna, y que el calcio favorecería el macerado y al mantener los sulfatos a raya, prevendríamos un amargor demasiado áspero.
Tanto en el libro de Ray Daniels como en el de George y Laure Fix, encontraremos información más detallada acerca del agua de Viena. Como premisa, si tienes que calcificar el agua, se recomienda hacerlo con cloruro de calcio para no añadir sulfatos de más.
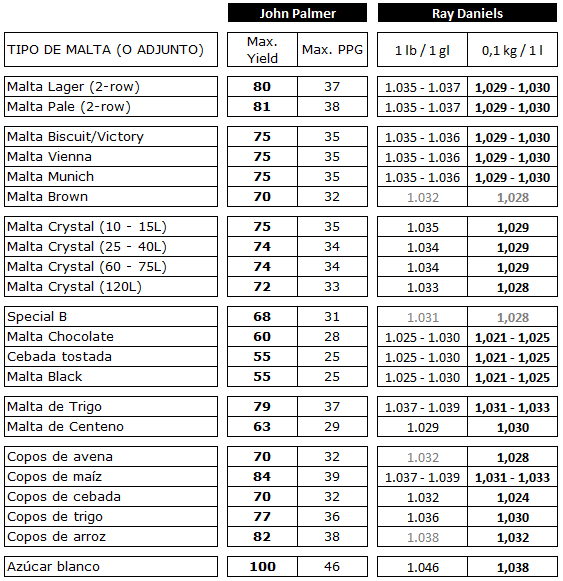
Maltas
Para quien no lo sepa, en el libro “Designing Great Beers”, se hace un ejercicio muy curioso. Resumiendo un poco, lo que hace es coger un montón de recetas ganadoras (y finalistas) de varios años en la National Homebrewer Competition y analizarlas a conciencia, creando una serie de patrones teniendo en cuenta los ingredientes y procesos utilizados. Con esto consigue deducir y/o interpretar cómo son los estilos de acuerdo a las elaboraciones de los cerveceros caseros más avezados. En cierto modo, tiene su lógica y su encanto. El concurso juzga en la misma categoría tanto a las recetas Vienna como las de la Märzen, pero cuando puede, divide los consejos entre los dos subestilos, y eso está recogido en mi resumen.
Teniendo en cuenta esto, Ray Daniels nos dice que la mayoría de las recetas están basadas en una mezcla de cuatro ingredientes. Concretamente (y por orden de importancia): malta Munich, malta de dos hileras (la 2-rows, popular en los Estados Unidos), malta Pils y malta Vienna.
En un sentido práctico y teniendo en cuenta que estamos en Europa, y que el estilo es de origen europeo, no convendría complicarse la vida usando malta americana de dos hileras. Por lo cual, podemos centrarnos en un triunvirato maltero: Munich – Pils – Vienna. Lo que ya nos da una idea de que estamos buscando un perfil maltoso de forma seria.
Yendo un paso más allá, las funciones de la malta Pils y la de dos hileras es la misma (aportar la mayoría de los azúcares fermentables, así como no aportar demasiado color), por lo que podemos sumar la parte de dos hileras a la Pils.
Por otro lado, las funciones de la malta Munich y la Vienna es la misma (y la manera de producir ambas maltas, muy similares también, y fácilmente sustituibles entre ellas), aportar más sabor a malta, y colores dorados y ambarinos.
En el análisis de las recetas, las combinaciones de dichas maltas son muy variopintas. Si bien es verdad que la mayoría de ellas contemplaba un 80-90% de la suma de estas cuatro, hay de todo. Lo más usual era un 50-60% de malta base + 30-40% de malta Munich/Vienna. Pero en algunos casos los cerveceros aportaban más malta Munich/Vienna que maltas bases en proporción. Esto es, un 60-70% de malta Munich/Vienna.
Muchas de las recetas también usaban malta Crystal o Caramelo (en torno a un 7-9% del grano total) y 6 de cada diez incluían malta CaraPils y malta de trigo (entre 3-7% del grano total). Otras maltas como la Chocolate, aparecen, pero de manera marginal. El trigo solo también es bastante marginal, así como otras maltas tipo Aroma.
En conclusión, obtendrías buenos resultados manteniendo al menos un 90% del grano total con una mezcla de Pils – Munich – Vienna en cualquier proporción, y si quieres darle otro toque, rellenar con Cristal, alguna otra malta tostada, CaraPils y/o malta de trigo.
Para el macerado de las maltas, ninguno en todas esas recetas usó un macerado por decocción, sino que se limitaron a la infusión simple, en rango de 67 °C. Con una densidad inicial media para las Märzen/Oktoberfest de 1,057. Así que podemos deducir sin miedo a equivocarnos que gracias a las características de las maltas modernas, podemos conseguir resultados muy buenos dejando de lado procesos engorrosos como las decocciones, y huyendo de complicaciones.
Lúpulos
El análisis de las recetas muestran unos rasgos de lupulización relativamente sencillos. Con unos niveles de BU:GU [¡plink!] de entre 0,50-0,57 para las Märzen, con unos IBUs teóricos finales de 20-46 (aunque se insiste en apuntar al rango 25-35), buscando un amargor bajo (como demanda el estilo) a moderado (por decisión del cervecero).
Como no se busca sabores a lúpulo, el dry hopping es marginal, y el top 3 de los lúpulos usados fueron el Hallertau, el Liberty y el Saaz (a los que les sigue el Tettnanger, el Perle y el Styrian Golding). Teniendo en cuenta que las elaboraciones son meramente americanas, en Europa hay más facilidad de conseguir las variedades europeas, tales como el Saaz y el Hallertau, siendo más fieles al estilo histórico.
Las adiciones de lúpulo se aproximaban a 1,1 – 1,2 gramos/litro para sabor y aroma (entre los 10-29 minutos), además de la de amargor, que serviría para cuadrar los IBU.
Levaduras
La levadura reina en las elaboraciones del análisis era de la cepa Bavarian Yeast, muy recomendable para acentuar el carácter de la malta. En el capítulo no especifica cual, concretamente, pero tanto Whitelabs como Wyeast tienen su cepa Bavarian Lager, que serían la WLP920 y la Wyeast 2206, respectivamente. La segunda en el podio sería la Weihenstephan 308 (Wyeast 2308). Y la alternativa a ambas, la cualquiera que cuadre en una cerveza lager, como la Wyeast 2124 Bohemian Lager, o las WLP820 Oktoberfest Lager y la WLP830 German Lager.
La temperatura media de fermentación para todas las elaboraciones fue de unos 10 °C. Y la maduración o fermentación secundaria resulta sorprendentemente corto para lo que se recomienda, de entre cuatro y cinco semanas a una media de 0 y 3 °C. Lo usual sería más de ocho semanas, aunque gracias al análisis de Ray Daniels sabemos que aunque siendo lo ideal, no es lo indispensable, y al menos, respetar los 2-4 °C para la guarda en frío.
No se ofrecen alternativas de levadura lager en polvo, por estar más limitadas, pero si nos empeñamos en usar levaduras secas, las elecciones serían la Saflager S-23 o la W-34/70, esta última también de Weihenstephan.
Un paso más allá
Sabiendo que el libro de Ray Daniels, clásico entre los clásicos, ya tiene sus añitos, me he dado un paseo por los seis últimos años de la revista Zymurgy, cuya publicación de Septiembre/Octubre de cada año publica las recetas ganadoras de la National Homebrewer Competition, en cada una de sus categorías. Y podemos sacar conclusiones aún más interesantes, ya que ciertos parámetros van evolucionando, aparecen nuevas maltas de nuevos fabricantes, o se comercializan nuevas cepas de levadura… y creo que es conveniente echar un vistazo.
De las seis últimas recetas (2015-2010) ganadoras en la categoría “European Amber Lager”, la mitad eran del subestilo Märzen/Oktoberfest (2014, 2013 y 2010). No es mala información, teniendo en cuenta que ganaron entre 161, 159 y 145 participantes, respectivamente.
El planteamiento de la receta ganadora de 2014 era de un 73% malta Vienna y un 25% malta Munich II, con un 2% de malta Acid (todas de Weyermann). Usó un macerado de doble decocción. Tiene una lupulización muy aburrida, pero efectiva, con una sola cuota de lúpulo Perlé a los 60 minutos, hirviendo 60 minutos. Partió de una DI de 1,056 y usó la levadura WLP833 German Bock Lager para bajar a 1,012. El calendario de fermentación es muy efectivo, con 10 días a 9 °C, 7 días a 14 °C y una guarda en frío de 60 días a -1 °C.
En 2013, la medalla de oro usó un 44% de malta Pilsener (la tradicional de Weyermann, malteada en el suelo), un 30% de malta Munich (Weyermann 5-7) y un 26% de malta Vienna (Weyermann 3,5). Usó una decocción simple y lupulizó con Millenium usando la técnica “First Wort Hopping” y luego con el Tettnanger a los 30 y 10 minutos para completar unos IBU teóricos de 24,6 con un hervido total de 90 minutos. Fermentó con la Wyeast 2633 Oktoberfest Blend lager para bajar de 1,056 a 1,014 y siguió un calendario de fermentación bastante práctico: 14 días a 10 °C, 2 días a 20 °C como descanso de diacetil, y luego bajó 1 °C/día hasta llegar a 1 °C durante 90 días.
La otra receta ganadora, la de 2010, dice tener un 91% de malta Vienna y el 9% restante lo divide a partes iguales en maltas Munich, Dextrin, Melanodin y Acid. Macerar por infusión simple a 67 °C y también tiene “First Wort Hopping” con Centennial, para luego hervir 105 minutos y lupulizar con Hallertau a los 15 y 5 minutos, completando 21 IBU teóricos. Fermenta con la WLP833 German Bock Lager (como la que gana en 2014) y baja de 1,058 a 1,014, fermentando 14 días a 10 °C y 42 a 2 °C (sin descanso de diacetil, lo que no acabo de creerme).
Final
A lo largo del post hemos hecho un breve repaso histórico del estilo, hemos visto también que se trata de una cerveza bastante flexible en cuanto a formulación y que deja bastante libertad al elaborador. Lo realmente interesante, como siempre, sería poder hacer varias versiones con diferentes planteamientos en las recetas y usar diferentes levaduras para dichos planteamientos. Sobre todo, antes de enviar la cerveza a un concurso.
La parte mala es, que teniendo en cuenta la limitación de espacio de la mayoría y las 8-10-12 semanas de guarda en frío, llegar a una conclusión efectiva respecto a mezcla de maltas, lupulización efectiva y elección de levaduras, nos llevaría años.